Kafka
In Big Data, a large volume of data is used. Regarding data, we have two main challenges:
- How to collect a large volume of data.
- Analyzing the collected data.
Implementing a messaging system is a common solution for those challenges.
Kafka is one of the most popular messaging systems today. It is designed for distributed, high-throughput systems to manage the queue and the data flow.
Kafka's architecture is designed based on several components and each component has its own unique role.
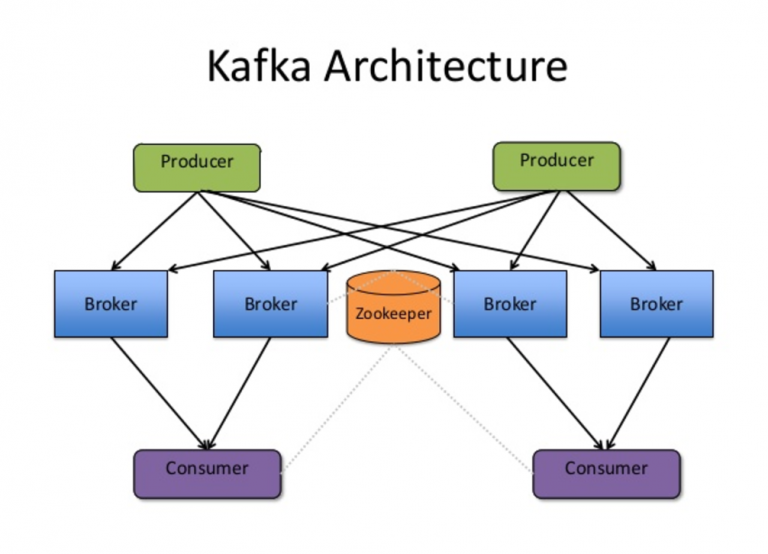
-
Broker – A Kafka cluster is made up of multiple Kafka Brokers. Each Kafka Broker has a unique ID. Kafka Brokers contain topic log partitions. Connecting to one broker bootstraps a client to the entire Kafka cluster.
-
ZooKeeper – A resource that is required for leadership election of Kafka Broker and Topic Partition pairs. Kafka uses Zookeeper to manage service discovery for Kafka Brokers that form the cluster. Zookeeper sends changes of the topology to Kafka, so every node in the cluster knows when a new broker joined, a Broker died, a topic was removed or a topic was added, etc.
-
Producer – Producers push data to brokers. When the new broker is started, all the producers discover it and automatically sends a message to that new broker.
-
Consumer – Consumers fetch data from the brokers. Kafka consumer divides partitions over consumer instances within a consumer group. Each consumer in the consumer group is an exclusive consumer of a
fair shareof partitions. This is how Kafka does load balancing of consumers in a consumer group. Consumer membership within a consumer group is handled by the Kafka protocol dynamically. If new consumers join a consumer group, it gets a share of partitions. If a consumer dies, its partitions are split among the remaining live consumers in the consumer group. This is how Kafka does fail over of consumers in a consumer group.
Elastigroup Configuration
To provide availability of the Kafka clusters on EC2 Spot instances, Elastigroup should be configured as described below.
Replication Factor
The purpose of adding replication in Kafka is for stronger durability and higher availability. We want to guarantee that any successfully published message will not be lost and can be consumed, even when there are server failures
The parameter of the replication factor located at the server.properties file with the value offsets.topic.replication.factor=2, replication factor 2 means 3 copies of the data as the diagram below shows, once we have 3 copies that are spread on different A-Z's, this will be configured by using different Rack ID's and explained at the next section, we are safe from data failure.
Shard aware Location – Rack ID
Let's assume an example with 6 brokers.
Brokers 0, 1, and 2 are on the same rack (Availability Zone), and brokers 3,4 and 5 are on a separate rack. Instead of picking brokers in the order of 0 to 5, we order them: 0, 3, 1, 4, 2, 5 – each broker is followed by a broker from a different rack. In this case, if leader for partition 0 is on broker 0, one of the replicas will be on broker 3 which is on a completely different rack. If the first rack goes offline, we know that we still have a surviving replica and therefore the partition is still available. This will be true for all replicas, so we have guaranteed availability in case of rack failure.
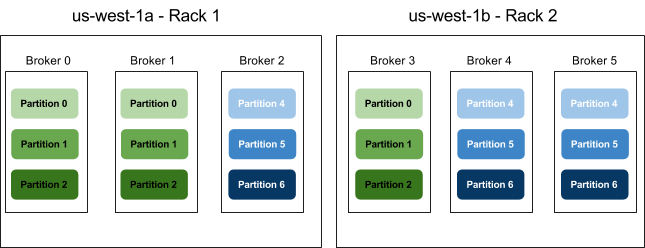
As mentioned before, we recommend to configure is replication factor of 2, and to deploy one broker as On Demand instance and the other one as Spot, this can be configured by changing the Rack ID when creating an instance, once the instance is created a USER DATA configuration script checks if this instance is an on demand, if yes it will deploy the instance on Rack 1. If the instance is Spot the Rack ID will be 2 and the USER DATA script will update the server.properties file with the relevant Rack ID number.
You can specify that a broker belongs to a particular rack by adding a property to the broker config:
Location -
config/server.properties
Value -
broker.rack=my-rack-id #example `broker.rack=1`>
The most powerful feature, in this case, is the Elastigroup Stateful feature. We don't need to wait for the cluster to rebalance because the broker will come back from failure with the volume disk attached with the data updated to the moment the server has terminated.
In order not to sync all the data from the start to another broker we recommend to increase the max delay time of replication between brokers to 5 minutes (in that time we will create a new instance to the cluster and the instance will be ready to be back in the cluster).
Add to the server.properties file the value: Replica.lag.time.max.ms=300000
Consumer
When running consumer on EC2 Spot instances you will need to make sure that the consumer server will rejoin to the same group upon replacement, so the value group.id in the consumer config file must be correct.
It can be done either by using the 'USER DATA' script or by preserving the instance root volume.
Consumers are Stateless
Consumers notify the Kafka broker when they have successfully processed a record, which advances the offset.
If a consumer fails before sending commit offset to Kafka broker, then a different consumer can continue from the last committed offset.
If a consumer fails after processing the record but before sending the commit to the broker, then some Kafka records could be reprocessed. In this scenario, Kafka implements the at least once behavior, and you should make sure the messages (record deliveries) are idempotent.
So as we can see from this behavior there is no problem running consumers on spot instances.