Elastigroup FAQs
Elastigroup
AWS, Azure, GCP: What regions does Spot support for my cloud provider?
AWS Regions
us-east-1, us-east-2, us-west-1, us-west-2, ca-central-1, sa-east-1, eu-central-1, eu-west-1, eu-west-2, eu-west-3, eu-north-1, ap-south-1, me-south-1, ap-southeast-1, ap-southeast-2, ap-northeast-1, ap-northeast-2, ap-east-1, cn-north-1, cn-northwest-1, ap-northeast-3, af-south-1, eu-south-1, us-gov-east-1, us-gov-west-1, cn-north-1, cn-northwest-1.
Azure Regions
australia-central, australia-central-2, australia-east, australia-south-east, brazil-south, canada-central, canada-east, central-india, central-us, east-asia, east-us, east-us-2, france-central, france-south, germany-central, germany-north, germany-north-east, germany-west-central, japan-east, japan-west, korea-central, korea-south, north-central-us, north-europe, norway-east, norway-west, south-africa-north, south-africa-west, south-central-us, south-east-asia, south-india, switzerland-north, switzerland-west, uae-central, uae-north, uk-south, uk-west, west-central-us, west-europe, west-india, us-gov-arizona, us-gov-texas, us-gov-virginia, west-us, west-us-2, west-us-3.
GCP Regions
us-east1, us-east1, us-east1, us-east4, us-east4, us-east4, us-central1, us-central1, us-central1, us-central1, us-west1, us-west1, us-west1, europe-west4, europe-west4, europe-west4, europe-west1, europe-west1, europe-west1, europe-west3, europe-west3, europe-west3, europe-west2, europe-west2, europe-west2, asia-east1, asia-east1, asia-east1, asia-southeast1, asia-southeast1, asia-southeast1, asia-northeast1, asia-northeast1, asia-northeast1, asia-south1, asia-south1, asia-south1, australia-southeast1, australia-southeast1, australia-southeast1, southamerica-east1, southamerica-east1, southamerica-east1, asia-east2, asia-east2, asia-east2, asia-northeast2, asia-northeast2, asia-northeast2, europe-north1, europe-north1, europe-north1, europe-west6, europe-west6, europe-west6, northamerica-northeast1, northamerica-northeast1, northamerica-northeast1, us-west2, us-west2, us-west2.
AWS, Azure, GCP: Why is an on-demand instance launched instead of a spot instance?
An on-demand instance may be launched instead of a spot instance even if a spot instance is available in the markets selected in the Elastigroup.
You can set Equal AZ Distribution for cluster orientation in Elastigroup. Despite this, Spot may prioritize a certain availability zone to maintain equal distribution.
An Elastigroup may have Equal AZ Distribution set for cluster orientation, but the system sometimes prioritizes a certain availability zone to maintain equal distribution. When no spot instances are available, an on-demand instance spins up in the relevant availability zone.
AWS, Azure, GCP: Why can’t I spin new instances (duplicate tags)?
You can get this message when the group or cluster is scaling up instances:
Can't Spin Instances: Code: ValidationError, Message: can't spin spot due to duplicate tags error
This happens if you have duplicate tags configured:
- The cluster has more than one of the same custom tags.
- You created a custom tag key with spotinst—Spot automatically creates scaling tags that start with spotinst, resulting in multiple identical tags.
AWS, Azure, GCP: Why can I only see some of the logs in the Spot console?
The log file shows up to 1,000 items at a time.
In the Spot console, try filtering on a shorter date range, a severity, or a specific resource.
You can also export the logs to an S3 bucket.
AWS, Azure: Where are the agent logs saved?
The Spotinst agent logs are saved:
- Linux: /var/log/spotinst/spotinst-agent.log
- Windows: C:\Spotinst
AWS, GCP: Can I log events for the Spotinst SDK for Python?
You can get a detailed response for the Python SDK. For example, you can include request IDs and times.
Add the log_level to your scripts: client = session.client("elastigroup_aws", log_level="debug").
Change the session client from elastigroup_aws to the client you need.
AWS: Can Elasticsearch integrate with Spot?
You can stream Elastigroup logs to an AWS S3 bucket. Then, you can configure Elasticsearch and Kibana to collect logs from the S3 bucket:
-
Elastigroup add this code to the JSON:
"logging": {
"export": {
"s3": {
"id": "di-123"
}
}
}
AWS: Why do some on-demand instances in my AWS account use reservations or savings plans with utilizeCommitments: false?
You can have on-demand instances running in your group/cluster using reserved instance/savings plan even if you have set utilizeCommitments: false.
This happens because of:
- AWS commitments coverage: When an on-demand instance launches in AWS, if there are any existing reservation or savings plan AWS may use them. AWS has its own way of deciding if an instance can be covered by a commitment plan. If the instance meets certain criteria, it will be covered if there's available space. This is how AWS handles reservations and savings plans. This happens even if you select utilizeCommitments: false.
- Elastigroup/Ocean’s explicit commitment utilization: If you’ve selected utilizeCommitments: true, Spot imitates AWS’s method to help you utilize all the commitment plans for your AWS account. If there is free space in the commitment plan and markets, your on-demand instances run reserved instances/savings plans.
An on-demand instance marked as a reserved instance/savings plan doesn't always mean it will launch as a commitment plan. There can be other reasons for launching on-demand instances, such as when there is no spot capacity available or when certain requirements in Ocean need an on-demand instance. Then, if the on-demand instance is eligible, it will automatically use a commitment plan if there's space.
Spot cannot control how AWS automatically handles commitment plan utilization. In addition, Spot cannot prioritize which on-demand instances should be on a commitment plan and which should not.
AWS: What’s the difference between lifecycle OD(SP) and lifecycle OD(RI)?
- OD(SP) is an on-demand instance with a savings plan. An OD(SP) is an on-demand instance that utilizes a savings plan (SP) commitment. Savings plans have a flexible pricing model that offers significant savings on AWS usage, in exchange for a commitment to use a specific amount of resources over a one- or three-year term. The utilization of a Savings Plan is determined by AWS, based on available commitments.
- OD(RI) is an on-demand instance with a reserved instance. An OD(RI) is an on-demand instance that utilizes a reserved instance (RI) commitment. Reserved instances give a billing discount applied to the use of on-demand instances in your account. Like savings plans, reserved instances require a commitment to use a specific instance type in a specific region for a one- or three-year term. AWS automatically applies the reserved instance discount to eligible instances based on the availability of the reserved instance commitment.
AWS: Why is my on-demand instance utilized as a reserved instance/savings plan?
When is an on-demand (OD) instance a reserved instance (RI), savings plan (SP), or full-priced on demand?
When launching an on-demand instance, you cannot specifically request it to run as a reserved instance or savings plan.
AWS decides according to:
- If the market matches a free zonal reserved instance commitment, then the instance is a reserved instance.
- If the market matches a free regional reserved instance commitment, then the instance is a reserved instance.
- If the market matches a free EC2 instance savings plan commitment, then the instance is a savings plan.
- If there is any free compute service plan commitment, then the instance is a savings plan.
- Otherwise, the instance will run as a full-price on-demand instance.
Throughout the lifetime of an instance, it can change its “price” whenever there’s any change in the commitments utilization rate. For example, if an instance is running as a full price on-demand instance, and another instance that was utilizing a compute savings plan commitment was terminated, the first instance will start utilizing this commitment if its hourly price rate has enough free space under this commitment. It might take a couple of minutes for this change to show, but since the billing is being calculated retroactively, in practice it’s starting to utilize the commitment right away.
AWS: What are the minimum permissions Spot needs to my AWS environment?
You can see the list of permissions required for Spot in Sample AWS policies.
AWS: What is the default draining timeout?
Draining timeout is the time in seconds to allow the instance or node to be drained before terminating it.
The default draining for:
- Elastigroup is 120 seconds
- Ocean is 300 seconds
- ECS (/elastigroup/Ocean) is 900 seconds
AWS: Can my shutdown scripts have 32-bit code (PowerShell)?
Normally, Elastigroup scripts in PowerShell run in 64-bit. You may need part of your code to run in 32-bit. You can do it by adding:
Set-Alias Start-PowerShell64 "$env:windir\sysnative\WindowsPowerShell\v1.0\powershell.exe"
Start-PowerShell64 <command-here>
For example, if you’re using it for Stop-WebAppPool -Name *, you can use this code:
<powershell>
Start-Transcript -Path C:\Temp\shutdown_script.log -append
New-Item D:\Logs\shutdown_started.txt
Set-Content D:\Logs\shutdown_started.txt 'shutdown-script is running - running webpool Stop'
Set-Alias Start-PowerShell64 "$env:windir\sysnative\WindowsPowerShell\v1.0\powershell.exe"
Start-PowerShell64 {Stop-WebAppPool -Name *}
Stop-Transcript
Start-Sleep -s 300
AWS: How can I update the instance metadata (IMDS) in my cluster?
Instance metadata service (IMDS) is data about your instance that you can use to configure or manage the running instance or virtual machines. IMDS comes from the cloud providers. The metadata can include instance ID, IP address, security groups, and other configuration details.
Instance metadata service version 2 (IMDSv2) addresses security concerns and vulnerabilities from IMDSv1. IMDSv2 has more security measures to protect against potential exploitation and unauthorized access to instance metadata.
Scenario 1: Ocean and Elastigroup
You can define metadata for autoscaling groups in AWS that gets imported when you import the groups from AWS to Spot. You can manually configure them in Spot to use IMDSv2.
-
Follow the Ocean AWS Cluster Create or Elastigroup AWS Create API instructions and add this configuration for the cluster:
"compute": {
"launchSpecification": {
"instanceMetadataOptions": {
"httpTokens": "required",
"httpPutResponseHopLimit": 12,
"httpEndpoint": "enabled"
}
}
} -
Apply these changes to the currently running instances so the clusters are restarted and have the new definitions:
Scenario 2: Stateful Node
When a stateful managed node is imported from AWS, Spot creates an image from the snapshot. When an instance is recycled, the metadata configuration is deleted and changes to IMDSv1.
You can use your own AMI and configure IMDSv2 on it. All instances launched after recycling will have IMDSv2 by default.
-
Configure IMDSv2 on your AMI:
-
If you're creating a new AMI, you can add IMDSv2 support using AWS CLI:
aws ec2 register-image Let me know if there is anything else I can help you with.
--name my-image \
--root-device-name /dev/xvda \
--block-device-mappings DeviceName=/dev/xvda,Ebs={SnapshotId=snap-0123456789example} \
--imds-support v2.0 -
If you use an existing AMI, you can add IMDSv2 using AWS CLI:
aws ec2 modify-image-attribute \
--image-id ami-0123456789example \
--imds-support v2.0
-
-
In the Spot console, create a stateful node with the custom AMI.
AWS: What does autoTag in CloudFormation do?
When you use autoTag in CloudFormation, Spot adds these tracking tags to instances provisioned as part of the custom resource:
spotinst:aws:cloudformation:logical-idspotinst:aws:cloudformation:stack-namespotinst:aws:cloudformation:stack-id
You can see examples of autotagging in:
AWS: Can I monitor detached instances using tags?
You can monitor your detached instances using tags. When an instance gets detached, Spot tags it with:
Key: spotinst:aws:ec2:stateValue: detached
For a spot instance, the spot request is tagged. For an on-demand instance, the instance is tagged.
AWS: How can I set a memory-based scaling policy in Elastigroup?
Scaling policies typically include CloudWatch metrics such as CPU utilization, network out, and latency.
You can configure a custom scaling policy that is based on another metric. For example, you may want to scale according to memory utilization.
-
To set a simple scaling policy, revert the Elastigroup configurations to the legacy design:
- In the Spot console, go to Elastigroup > Groups, and click on the name of an Elastigroup.
- Go to Actions > Edit Configuration.
- Click Revert to Legacy Design.
-
Click Scaling > Simple Scaling Policies.
-
Select Up Scaling Policies or Down Scaling Policies and click Add Policy.
-
Set these parameters:
- Policy Type: Simple scaling
- Source: AWS CloudWatch
- Auto Scale Based On: Other
- Namespace: Custom
- Custom Namespace: CWagent
- Metric Name: this AWS document contains the metrics you can use. These metrics are collected by the CloudWatch agent. For example, you can use mem_used or mem_used_percent.
-
Verify the CloudWatch agent is installed.
AWS: Can I roll my Elastigroup in Ansible?
You can roll your Elastigroup in Ansible if you have the roll_config in your Ansible configuration:
roll_config:
description:
- (Object) Roll configuration.;
If you would like the group to roll after updating, please use this feature.
Accepts the following keys -
batch_size_percentage(Integer, Required),
grace_period - (Integer, Required),
health_check_type(String, Optional)
AWS: How do I create spot interruption notifications?
You can use AWS EventBridge to send spot interruption warnings to the Spot platform in real time. These warnings are pushed by AWS at an account level and are region-specific. You'll need to set up notifications for each account and region.
- In your AWS console for the EventBridge page, make sure the EventBridge status is Inactive.
- Reestablish the connection: a. Open your AWS console and select the region. b. Go to the AWS CloudFormation service. c. Create a stack with new resources for a specific region, or create a StackSet for multiple regions. d. Select create from an S3 URL and use this template URL: https://spotinst-public.s3.amazonaws.com/assets/cloudformation/templates/spot-interruption-notification-event-bridge-template.json. e. Click Next. f. Fill in the stack name, spot account ID, and Spot token, then click Next. g. Repeat for each active region.
AWS: Why doesn’t Spot gracefully terminate instances if AWS gives a 2-minute termination notice?
AWS has a 2-minute warning before terminating spot instances. In reality, the warning doesn’t always give you the full 2 minutes. Sometimes, it can be as short as a few seconds.
When AWS terminates an instance, the machine status is updated regardless of the notification. Elastigroup and Ocean monitor the instance's status and can immediately launch a replacement spot instance. For this to happen, capacity must be available in the AWS market. Spot can’t always run the shutdown script in time due to capacity.
You can get higher availability by including:
- More instance types and availability zones for the group/cluster
- Fallback to on-demand
AWS: Why can’t I see all my AWS IAM roles when setting up a cluster/group?
When you’re in a cluster or group, you only see roles associated with the instance profile.
AWS: Why can’t I connect to an instance in Spot using SSH?
It’s possible that you can connect to your AWS instance using SSH but not your Spot instance, even with the same VPC, subnet, security group, and AMI.
One of the reasons this can happen is if you’re using enhanced networking and aren’t using the default eth0 predictable network interface name. If your Linux distribution supports predictable network names, this could be a name like ens5. For more information, expand the RHEL, SUSE, and CentOS section in Enable enhanced networking on your instance.
AWS: Why is EBS optimization disabled on instances optimized by default?
Amazon EBS–optimized instances use an optimized configuration stack and provide additional, dedicated bandwidth for Amazon EBS I/O.
Instances that are EBS-optimized by default are optimized regardless of the parameter settings. There is no need to enable EBS optimization and no effect if you disable EBS optimization in AWS or in Spot.
If an instance type isn’t EBS-optimized by default, you can enable optimization:
- In the Spot console, go to the Ocean cluster or Elastigroup.
- Click Compute > launchSpecification.
- Set ebsOptimized to true.
AWS: What happens if I change the spotPercentage to 0?
If you change the Spot % to 0, your already running spot instances do not automatically change to on-demand in a cluster/group.
You need to:
The automatic process only happens when changing the Spot % from on-demand instances to spot (fix strategy in Elastigroup, Ocean).
AWS: Why is the Target_Group health check status unknown?
You may get an unknown status for the target_group if:
- The instance status is in state initial. This means the instance is still registering to the target group or performing the initial health check.
- There isn’t enough data:
- Elastigroup didn’t get the instance status per target group for each of the target groups in the Elastigroup. Only one status per instance is saved, then aggregated based on all target groups.
- If there’s only one target group in the Elastigroup, then data wasn’t received from AWS.
- The grace period ended and the instance didn’t get a healthy status from the target group health check.
You can see the registered targets and their statuses in AWS.
AWS: Does autohealing work on locked instances?
You can lock specific instances to prevent them from being scaled down during autoscaling. Instance protection doesn’t work on unhealthy instances. The unhealthy instance handler starts a replacement as a part of the autohealing process, which tries to detach the instance. The detach instances command doesn’t take instance protection into account.
AWS: Can I use a custom proxy client for Spot health check service?
Yes, you can make changes to how the proxy agent works.
The Spot health check service is a proxy between Spot hosts and your EC2 private instances in your VPC. Spot triggers the proxy service on each check. The proxy communicates with your private instances in the VPC and sends the results to Spot. When an instance is marked as unhealthy, and the Elastigroup Health Check type is set to HCS, Spot replaces it with a new instance according to the Elastigroup config.
You can create a custom proxy agent based on the Spot health check service API.
AWS: Can I configure a scaling policy for the latency metric?
You can create a scaling policy for latency.
-
In the Elastigroup, go to the Scaling tab.
-
Under Simple Scaling Policies/Up Scaling Policies, click Add Policy.
-
Select these parameters:
- Auto Scale Based on: Other
- Namespace: AWS/Application ELB
- Metric Name: TargetResponseTime
- Dimensions – Name: LoadBalancer
- Dimensions – Value: this is the ARN of the load balancer, for example:
loadbalancer/app/{load-balancer-name}/{xxxxxxxxxxx}
-
Click Next.
AWS: If Utilize Reserved Instances is enabled, how does scaling work?
By default, Elastigroup monitors the status of your account's reservations and acts accordingly at the launch time of an on-demand instance. When an on-demand instance is scaled up, if the account has an available reservation to use in the specific market (instance type + availability zone), Elastigroup will utilize it and will use the reserved instance payment method.
If Utilize Reserved Instances is enabled, it automatically triggers constant attempts to revert the group's instances to on demand (reserved instance) if there are available reservations. It triggers a replacement for all instances, even spot, and uses your account's available reservations. The priority of launching instances in this group is:
- It will see if there is an option to launch a reserved instance
- If it cannot, it will launch a spot instance.
- If a spot instance is unavailable for any reason, an on-demand instance will be launched based on the fallback to on-demand configuration.
AWS: Why am I getting a Scale down as part of instance recovery or Scale up as part of instance recovery message?
You can get this log message if:
-
The instance is scaled down because of AWS’s capacity.
-
An instance replacement was initiated because of AWS’s capacity. A new instance is launched to replace an instance that was taken back because of AWS’s capacity.
-
An instance is manually terminated in AWS.
This means that there are no spot markets available to launch spot instances. You can add more spot markets to improve availability:
- For Elastigroup, instance types and availability zones.
- For Ocean, instance types and availability zones.
AWS: Why am I getting an Out Of Strategy - On Demand No Replacement Will Be Created message?
If your Elastigroup has more on-demand instances than the on-demand workload capacity, Elastigroup tries to revert to spot instances. This is called fix strategy.
When this happens, you can get this message in the Spot console logs:
Out Of Strategy - On Demand Above Strategy: Desired OD count: 0.0. Actual OD Count: xx. No Replacement Will Be Created Due To The Following Reason: Account Out Of Strategy procedure is currently suspended.
The fix strategy can be paused if:
- There are no spot markets available to launch spot instances. You can add more instance types and availability zones to your group to improve availability.
- The spot instance vCPU quota is exceeded for your AWS account. You can request a quota increase from AWS.
AWS: Why can’t I spin new instances (tag policies)?
If you’re getting this message:
Can't Spin Spot Instances: Message: The tag policy does not allow the specified value for the following tag key: 'XXX'.
It means a tag defined in your Elastigroup or cluster doesn’t comply with AWS’s tag policy.
-
In the Spot console, go to:
- Elastigroup > Groups > click on the Elastigroup > Log.
- Ocean > Cloud Clusters > click on the cluster > Log.
-
Identify the problematic tag keys/values.
-
Review AWS’s tag policies and how to set up tag policies.
-
In the Spot console, update the tag keys/values:
- Elastigroup > Groups > click on the Elastigroup > Actions > Edit Configuration > Compute > Advanced Settings.
- Ocean > Cloud Clusters > click on the cluster > Actions > Edit Cluster > Compute.
The instance will be launched when the tags in Spot clusters/groups comply with the tag policy defined in AWS.
AWS: Why can’t I spin new instances (encoded authorization)?
You can get these messages when the group or cluster is scaling up instances:
Can’t Spin Instances: Message: You are not authorized to perform this operation. Encoded authorization failure messageCan’t Spin On-Demand Instances: Message: You are not authorized to perform this operation. Encoded authorization failure message
These messages could be related to service control policies (SCP). Keep in mind, Spot doesn’t get SCP information from AWS, so doesn’t know which instance types AWS blocks because of the SCP restrictions. As a result, Spot cannot launch a new instance of a different type.
-
You need to identify the reason for the error in AWS.
-
In the Spot console, update the instance types:
AWS: Why can't I spin new spot instances (InsufficientInstanceCapacity)?
This message is shown in the console logs if Ocean attempts to scale up a certain spot instance type in a particular availability zone. This happens because of a lack of capacity on the AWS side.
Can't Spin Spot Instances: Code: InsufficientInstanceCapacity, Message: We currently do not have sufficient m5.2xlarge capacity in the Availability Zone you requested (us-east-1a). Our system will be working on provisioning additional capacity. You can currently get m5.2xlarge capacity by not specifying an Availability Zone in your request or choosing us-east-1b, us-east-1c, us-east-1d, us-east-1f.
Ocean is aware of a pending pod and is spinning up an instance. Based on your current instance market, Ocean chooses the instance type in a particular availability zone and attempts to scale up. If it fails due to a lack of capacity, the error message is shown in the console logs.
You can solve this by:
- Having many instance types, so Ocean can choose the best available markets.
- Having multiple availability zones to provide more availability.
- For workloads that are not resilient to disruptions, configure the on demand label
spotinst.io/node-lifecycle.
AWS: Why can't I spin new instances (InvalidSnapshot.NotFound)?
You have scaling up instances for your Elastigroup or Ocean clusters and you get this message:
ERROR, Can't Spin Instances: Code: InvalidSnapshot.NotFound, Message: The snapshot 'snap-xyz' does not exist.
If you have a block device that is mapped to a snapshot ID of an Elastigroup or Ocean cluster and the snapshot isn't available, you will get this error. This can happen if the snapshot is deleted.
If you have another snapshot, then you can use that snapshot ID for the block device mapping. If not, you can remove the snapshot ID, and then the instance is launched using the AMI information.
-
Elastigroup: on the Elastigroup you want to change, open the creation wizard and update the snapshot ID.
-
Ocean: on the virtual node group you want to change, update the snapshot ID.
AWS: Why can't I spin new spot instances (MaxSpotInstanceCountExceeded)?
You can get this message if AWS's spot service limit is reached:
Can't Spin Spot Instances:Code: MaxSpotInstanceCountExceeded, Message: Max spot instance count exceeded
You may also get an email from Spot: Spot Proactive Monitoring | Max Spot Instance Count Exceeded. This email includes instructions for opening a support request with AWS, such as the instance type and region that triggered the error.
You can read the AWS documentation on spot instance quotas.
AWS: Why can’t I spin new instances (UnsupportedOperation)?
You can get this message when the group or cluster is scaling up instances:
Can't spin spot instance: Code: UnsupportedOperation, Message: The instance configuration for this AWS Marketplace product is not supported. Please see the AWS Marketplace site for more information about supported instance types, regions, and operating systems.
This typically happens if the group/cluster AMI product doesn’t support specific instance types in the group/cluster instance list.
-
Identify the AMI:
- Search AWS Marketplace for the AMI ID.
- Elastigroup: in the Spot console, go to Elastigroup > Groups > select the group > Group Information and click Details > productCodeId.
- Ocean: in the Spot console, go to Ocean > Cloud Clusters > select the cluster > Actions > Edit Cluster > Compute > Instance specifications > View AMI details > productCodeId.
-
Troubleshoot AWS Marketplace AMIs. For example, check the instance types, regions, and availability zones. You can compare the instance types in AWS with the Spot console:
- Elastigroup: in the Spot console, go to Elastigroup > Groups > select the group > Compute > Instance types.
- Ocean: in the Spot console, go to Ocean > Cloud Clusters > select the cluster > Actions > Edit Cluster > Compute > Instance types.
AWS: Why am I getting a Can't Spin On-Demand Instances: Code: InvalidKeyPair.NotFound message?
You can get this message if the key pair is missing or not valid: Can't Spin On-Demand Instances: Code: InvalidKeyPair.NotFound, Message: The key pair 'xxxxx' does not exist.
Update the key pair:
- In the Spot console, go to Elastigroup > Groups, and click on the name of an Elastigroup.
- Click Actions > Edit Configuration.
- In Basic Settings, select a Key Pair.
AWS: Why am I getting an instance launch failed because an EBS volume cannot be encrypted error?
If you get this error:
Spot Bad Parameters: Spot Request id: Optional{instance ID}. Code: bad-parameters Message: {timestamp}: Instance launch failed because an EBS volume cannot be encrypted. If your launch specification includes an encrypted EBS volume, you must grant the AWSServiceRoleForEC2Spot service-linked role access to any custom KMS keys.
Then there are missing permissions in the KMS custom key. You can configure KMS keys:
- From the same AWS account
- From a different AWS account (cross-account)
AWS: Why can’t I create an Elastigroup using Ansible (Spotinst SDK library is required)?
When creating an Elastigroup with Ansible, you may get this message:
TASK [create elastigroup] *****************************
fatal: [localhost]: FAILED! => {"changed": false, "msg": "the Spotinst SDK library is required. (pip install spotinst_sdk2)"}
You can get this message even if the library is installed. This can happen if Ansible uses the default Python version, which may not include the required packages.
- Check which version Ansible is using:
ansible localhost -a 'which python'. - Add Ansible Python interpreter (ansible_python_interpreter) to the ansible.cfg file.
AWS: Why am I getting a Cannot set both 'ondemand' and 'onDemandTypes' parameters message?
You may get the Cannot set both 'ondemand' and 'onDemandTypes' parameters message if ondemand is set for a single on-demand instance and onDemandTypes is set for multiple instance types.
Update the parameters:
-
In the Spot console:
- Go to Elastigroup > Groups.
- Select the Elastigroup and click Actions > Edit Configuration.
- Go to Compute > Instance selection.
- Update either On-demand Types or Preferred Spot Types.
-
In the Spot API. Set the parameter you’re not using to null.
-
In Terraform. Set the parameter you’re not using to null.
AWS: Why am I getting a Security group and subnet belong to different networks message?
You may see this message:
Security group sg-xxx and subnet subnet-xxx belong to different networks.
This can happen if the security groups or subnets aren’t compatible and are associated with the same virtual private cloud (VPC) network.
Update the subnetIds in the JSON:
- In the Spot console, go to Elastigroup > Groups and select the Elastigroup.
- Click Actions > Edit Configuration > Review > JSON > Edit Mode.
- In
compute:availabilityZones, remove the subnetIds listed in the error message.
AWS: Why am I getting a "value" contains a conflict between peers error?
When you import a new group to Elastigroup, you may get this error:
"value" contains a conflict between exclusive peers [resourceRequirements, spot]
This happens if the resourceRequirements value is null.
Remove the resourceRequirements field from the JSON file and reimport the group.
AWS: Why am I getting an exceeded the number of VPC security allowed per instance message?
You may get this message when creating or importing an Elastigroup or cluster if you reach your AWS service quota limit for security groups per network interface:
POST https://api.spotinst.io/aws/ec2/group?accountId=act-xxxxx: 400 (request: "xxxxx") SecurityGroupLimitExceeded: You have exceeded the number of VPC security groups allowed per instance.
You can request a quota increase from AWS.
AWS: Why am I getting an InsufficientFreeAddressesInSubnet message?
This can happen if the subnet doesn��’t have enough free IP addresses for your request. Free up IP addresses in this subnet.
AWS: Why am I getting an InvalidBlockDeviceMapping message?
You can get this message when the group's device name (for Block Device Mapping) and the AMI's device name do not match:
Can't Spin Spot Instance: Code: InvalidBlockDeviceMapping, Message: The device 'xvda' is used in more than one block-device mapping
- AMI - "deviceName": "xvda"
- Group's configuration - "deviceName": "/dev/xvda"
Change the device name from xvda to /dev/xvda on the group's side. Go to Actions > Edit Configuration > Review Tab > Switch to Json Edit format > Apply the changes and save.
AWS: Why am I getting errors when I try to delete a Beanstalk group?
When you delete a Beanstalk group, make sure you deselect Rollback beanstalk configuration. If Rollback beanstalk configuration is selected, you may get ASG errors.
- In the Spot console, go to Elastigroup > Actions > Delete Group.
- Deselect Rollback beanstalk configuration.
- Type the name of the group to confirm.
- Click Delete.
AWS: What are the deployment states for CodeDeploy?
This is the list of values you can get for the items.state in the Get CodeDeploy B/G Deployment API:
AWAITING_DEPLOYMENT_TO_FINISH
AWAITING_INSTANCES_LAUNCH
AWAITING_USER_DEPLOYMENT
ERROR
FINISHED
FINISHED_ERROR
FINISHED_STOPPED
LAUNCHING_NEW_INSTANCES
REMOVE_ALL_SUSPENSIONS
REMOVE_NEW_INSTANCES
REMOVE_OLD_INSTANCES
ROLLBACK_CREATE_DEPLOYMENT
ROLLBACK_REPLACE_OLD_NEW_INSTANCES
ROLLBACK_START
STARTING
STOPPING
TAG_INSTANCES_WITH_GREEN_TAG
UNSTABLE_DEPLOYMENT
VALIDATE_TAGS
WAIT_BEFORE_TERMINATION
Sample code with items.state:
"response": {
"status": {
"code": 200,
"message": "OK"
},
"items": [
{
"id": "cdbg-3ccf1234",
"groupId": "sig-87231234",
"state": "STARTING",
"config": {
"timeout": 20,
"tags": [
{
"tagKey": "ver",
"tagValue": "pink"
}
],
AWS: Can I increase the volume size of a stateful instance?
If you have a stateful Elastigroup with root or data volume persistence, you can increase the root or data volume size. Make sure the new volume is greater or equal to the existing volume size:
- In the AWS console, modify the volume. The new increased volume will show in the stateful instance.
- In the Spot console, configure block device mapping to override the size of the root or data volumes (if you are using snapshot backups). Then, recycle the stateful instance.
AWS: Is a stateful Elastigroup affected by the revert to preferred process?
Revert to preferred/reserved do not work for stateful groups because the processes require recycling, which causes downtime.
You can configure a maintenance window to control replacing on-demand instances with spot instances.
AWS: Can I use weights to control stateful Elastigroup capacity?
It’s not recommended to use weighted capacity for stateful Elastigroups. You can use it for non-stateful Elastigroups.
AWS: Can I delete a stateful instance from Spot and manage it in AWS?
You can remove your stateful instance from Elastigroup and manage it only in AWS:
-
In the Spot console, go to Elastigroup > Groups and select the stateful group.
-
Click Actions > Edit Configuration > Instance Type.
-
Go to Advanced and change Spot vs On-Demand Spot Percentage to 0%.
-
Click Next > Review > Update.
-
Select the stateful group and go to the Instances tab.
-
Select the managed instance and click Actions > Recycle. This will launch an on-demand instance.
-
Once the new on-demand instance is running, select the stateful group.
-
Click Actions > Edit Configuration.
-
Go to the Review tab > JSON > Edit Mode.
-
Change all persistence options to false and click Update. For example:
"persistence": {
"shouldPersistBlockDevices": false,
"shouldPersistRootDevice": false,
"shouldPersistPrivateIp": false
} -
Select the stateful group, and go to the Instance tab.
-
Select the instance, then click Actions > Detach. Make sure:
- Terminate Instances is not selected.
- Decrement Group’s Capacity is selected.
The on-demand instance is detached from the Elastigroup and you can manage it in AWS. You can choose to delete the Elastigroup if it’s not needed.
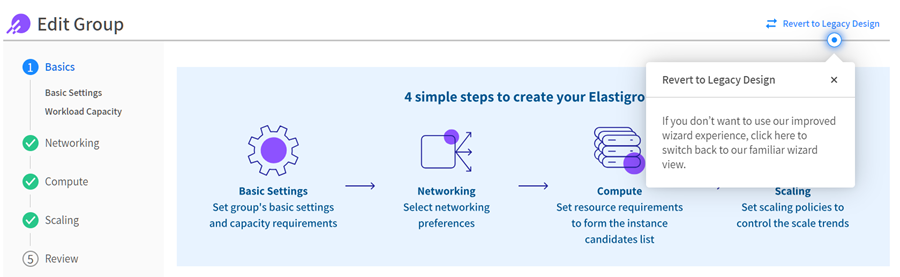
AWS: How can I switch to the legacy design?
You can switch the Elastigroup configurations to the legacy design:
- In the Spot console, go to Elastigroup > Groups, and select the name of an Elastigroup.
- Go to Actions > Edit Configuration.
- Select Revert to Legacy Design.
Azure: Can I use SSH to connect to an Azure VM?
Azure: Why am I getting a Failed to import virtual machine or The create/import has failed message?
You may get one of these error messages when you're trying to import VMs to Elastigroup:
Failed to import virtual machine. Could not retrieve custom image.The create/import has failed. The storage account https://{storage-account} that was defined for the boot diagnostic preferences was not found.”
This can happen when the image or storage account does not exist in the Azure portal. Elastigroup validates the resources configured in the VM before importing to make sure the import process will not fail.
Failed to import virtual machine
One of the resources checked is the image, which is taken from the VM JSON configuration file.
If you get the Failed to import virtual machine. Could not retrieve custom image. message, it means that Elastigroup couldn't find the custom image configured.
Find the name of the image in the Azure console. Go to VM details > JSON view > imageReference.
The create/import has failed
The storage account <Service account> that was defined for the boot diagnostic preferences was not found.
Before starting the import process, Elastigroup verifies that the service account configured exists in the subscription.
This error means that Elastigroup didn't find a valid storage account in the subscription.
Find the storage account URL in the Azure console. Go to VM details > JSON view > diagnosticsProfile.
Azure: Why am I getting a Failed to launch VM with RequestDisallowedByPolicy message?
When an instance is imported or launched, you may see this message in the Spot console:
ERROR Failed to launch virtual machine. Azure error code : RequestDisallowedByPolicy, message : Resource xxxxx was disallowed by policy. Policy identifiers: '[{"policyAssignment":{"name":"Allowed virtual machine size SKUs","id":"/providers/Microsoft.Management/managementGroups/mgid-bcbsri-root-001/providers/Microsoft.Authorization/policyAssignments/xxxxxx"},"policyDefinition":{"name":"Allowed virtual machine size SKUs","id":"/providers/Microsoft.Authorization/policyDefinitions/xxxxx"}}]'
This can happen if the policy limits launching VMs, which would limit launching instances.
Check the policy definition and policy assignment included in the message. See what part of the policy is blocking deployment.
Azure: Why is my VM showing offline in the Jenkins console?
You may have a VM showing as offline in the Jenkins console, but you can see that it’s running in the Azure console and in Spot’s Elastigroup.
You can see this message in the Jenkins console:
IP for agent is not available yet not attaching SSH launcher
This can happen if you launch agents via SSH and not JNLP, and you’re using private IPs configured in Elastigroup, but not in the Jenkins plugin. The Jenkins plugin then establishes a connection using a public IP.
Make sure your Jenkins plugin is set to use Private IPs.
GCP: How does the grace period work?
If an Elastigroup has a grace period of 1,000 seconds, the old instances are only detached after the full grace period of 1,000 seconds ends.
You can decrease the grace period for faster deployment.
GCP: Can I set up committed use discounts?
You can set up committed use discounts (CUDs) for clusters in Ocean and groups in Elastigroup. It cannot be used for virtual node groups.
Set up committed use discounts for:
GCP: Why am I getting an Invalid value for field error (disk size)?
You can get this message if instances aren’t starting:
Invalid value for field 'resource.disks[0].initializeParams.diskSizeGb': '80'. Requested disk size cannot be smaller than the image size (100 GB)
You need to increase the disk size for the Elastigroup:
- Go to the Elastigroup in the Spot console and click Actions > Edit Configuration > Compute.
- Update Boot Disk > Disk Size to be bigger than the configured disk size for the image.
GCP: Why can’t I spin new instances (boot disk architecture)?
If Elastigroup isn’t launching a VM, you might get this log message:
Can’t Spin Instance: Name: sin-abcd. Code: Error, Message: Invalid resource usage: 'Requested boot disk architecture (X86_64) is not compatible with machine type architecture (ARM64).'
This can happen because Elastigroup doesn’t validate VM architecture for GCP. You can troubleshoot this error in GCP.
GCP: Why am I getting a zone_resource_pool_exhausted (scale up) error?
You may get this log message when a VM is trying to scale up or launch VMs:
Can't Spin Instance: Name: abcde. Code: ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS,
Message: The zone 123 does not have enough resources available to fulfill the request, '(resource type:compute)'.
This can happen if the specific VM family and size aren’t available for a certain zone at the moment. Elastigroup or Ocean will try to automatically spin up a different VM in a different zone to compensate.
Integration: How can I update Terraform provider to the latest version?
You can:
- Download the Spot provider plugin and update it.
- Update the plugin from Terraform.
Integration: Can Elasticsearch integrate with Spot?
You can stream Elastigroup logs to an AWS S3 bucket. Then, you can configure Elasticsearch and Kibana to collect logs from the S3 bucket:
-
Elastigroup add this code to the JSON:
"logging": {
"export": {
"s3": {
"id": "di-123"
}
}
}
Integration: Can I use a custom AMI when cloning/importing an EMR cluster?
When you create an EMR cluster in the Spot console, you can use a custom AMI.
When you import a cluster using clone, you cannot use a custom AMI from the source cluster.
Integration: Why aren't my existing scaling policies imported with the EMR cluster?
Elastigroup has its own scaling and manages the instance groups. Clone and wrap don’t actually import the cluster:
- Clone: Elastigroup copies the configuration of an existing environment (including terminated environments) and creates a new cluster with this configuration.
- Wrap: Elastigroup manages scaling of only the task nodes of an existing EMR cluster.
Integration: How can I check if the Spotinst agent is running or enable it?
You can see the status of the Spotinst agent in the Spot console. Go to Elastigroup > Groups, and select the group > Instances. If the agent had a heartbeat in the last 2 minutes, it’s healthy.
In AWS, go to the instance and check:
- If the agent service is running:
service spotinst-agent status - The agent log, located
/var/log/spotinst.spotinst-agent.log
Integration: Can I disable Spotinst Agent logging?
You can run this script to stop Spotinst-Agent from sending logs to syslog:
sed -i 's/[Service]/[Service]\nStandardOutput=null\nStandardError=null/g' /lib/systemd/system/spotinst-agent.service
systemctl daemon-reload
systemctl restart spotinst-agent
Integration: Can I keep Jenkins Agent alive after a job finishes?
You can prevent an immediate termination of a specific spot instance that acted as an agent and carried out a certain Jenkins job. For example, this can be useful if you want to:
- Start additional jobs immediately after
- Optimize resource utilization
- Debug or review logs
Idle minutes before termination defines how long the Spot plugin should wait before terminating an idle instance.
Increase the Idle minutes before termination in the Spot Jenkins plugin.
Integration: Can I trigger the same Jenkins job on a different instance if it was interrupted?
You can retrigger the Jenkins job automatically if a node is interrupted. The interrupted job parameters are transferred to the new job.
Integration: Why should I use on-demand for EMR core node and spot for task nodes?
If a core instance is terminated, the group is permanently deleted. Core and masters are essential for the group to work well in EMR. As a result, it’s better to use on-demand instances for core nodes.
Task nodes can be replaced frequently as part of different instance groups, so it’s better to use spot instances for task nodes.
Integration: Is maintenance mode needed when I add Beanstalk environment variables?
Beanstalk environment variables are part of the application managed on the Beanstalk side, independently from the Elastigroup. Variables are automatically picked by instances that Spotinst launches into the environment.
Add variables in the Elastic Beanstalk console. Maintenance mode is not required as this change does not affect the infrastructure.
Integration: Why am I getting a group is in error state message when I try to delete an Elastigroup Beanstalk from the Spot console?
If you get this message when you try to delete an Elastigroup Beanstalk from the Spot console:
Group is in ERROR state and not in READY state, cannot delete it
You need to put the group in maintenance mode and detach the remaining instances, then you can delete the Elastigroup.
Keep in mind, you cannot delete a Beanstalk group if:
- The attached Beanstalk group was deleted.
- One of the resources was deleted, such as a security group or Elastic Beanstalk.
If you get an error, you can force delete the group by deselecting Rollback beanstalk configuration.
If you need to attach a Beanstalk environment, you can manually rebuild your Beanstalk environment.
Elastigroup Stateful Node
AWS, Azure, GCP: What regions does Spot support for my cloud provider?
AWS Regions
us-east-1, us-east-2, us-west-1, us-west-2, ca-central-1, sa-east-1, eu-central-1, eu-west-1, eu-west-2, eu-west-3, eu-north-1, ap-south-1, me-south-1, ap-southeast-1, ap-southeast-2, ap-northeast-1, ap-northeast-2, ap-east-1, cn-north-1, cn-northwest-1, ap-northeast-3, af-south-1, eu-south-1, us-gov-east-1, us-gov-west-1, cn-north-1, cn-northwest-1.
Azure Regions
australia-central, australia-central-2, australia-east, australia-south-east, brazil-south, canada-central, canada-east, central-india, central-us, east-asia, east-us, east-us-2, france-central, france-south, germany-central, germany-north, germany-north-east, germany-west-central, japan-east, japan-west, korea-central, korea-south, north-central-us, north-europe, norway-east, norway-west, south-africa-north, south-africa-west, south-central-us, south-east-asia, south-india, switzerland-north, switzerland-west, uae-central, uae-north, uk-south, uk-west, west-central-us, west-europe, west-india, us-gov-arizona, us-gov-texas, us-gov-virginia, west-us, west-us-2, west-us-3.
GCP Regions
us-east1, us-east1, us-east1, us-east4, us-east4, us-east4, us-central1, us-central1, us-central1, us-central1, us-west1, us-west1, us-west1, europe-west4, europe-west4, europe-west4, europe-west1, europe-west1, europe-west1, europe-west3, europe-west3, europe-west3, europe-west2, europe-west2, europe-west2, asia-east1, asia-east1, asia-east1, asia-southeast1, asia-southeast1, asia-southeast1, asia-northeast1, asia-northeast1, asia-northeast1, asia-south1, asia-south1, asia-south1, australia-southeast1, australia-southeast1, australia-southeast1, southamerica-east1, southamerica-east1, southamerica-east1, asia-east2, asia-east2, asia-east2, asia-northeast2, asia-northeast2, asia-northeast2, europe-north1, europe-north1, europe-north1, europe-west6, europe-west6, europe-west6, northamerica-northeast1, northamerica-northeast1, northamerica-northeast1, us-west2, us-west2, us-west2.
AWS: What’s the difference between lifecycle OD(SP) and lifecycle OD(RI)?
- OD(SP) is an on-demand instance with a savings plan. An OD(SP) is an on-demand instance that utilizes a savings plan (SP) commitment. Savings plans have a flexible pricing model that offers significant savings on AWS usage, in exchange for a commitment to use a specific amount of resources over a one- or three-year term. The utilization of a Savings Plan is determined by AWS, based on available commitments.
- OD(RI) is an on-demand instance with a reserved instance. An OD(RI) is an on-demand instance that utilizes a reserved instance (RI) commitment. Reserved instances give a billing discount applied to the use of on-demand instances in your account. Like savings plans, reserved instances require a commitment to use a specific instance type in a specific region for a one- or three-year term. AWS automatically applies the reserved instance discount to eligible instances based on the availability of the reserved instance commitment.
AWS: Why is my on-demand instance utilized as a reserved instance/savings plan?
When is an on-demand (OD) instance a reserved instance (RI), savings plan (SP), or full-priced on demand?
When launching an on-demand instance, you cannot specifically request it to run as a reserved instance or savings plan.
AWS decides according to:
- If the market matches a free zonal reserved instance commitment, then the instance is a reserved instance.
- If the market matches a free regional reserved instance commitment, then the instance is a reserved instance.
- If the market matches a free EC2 instance savings plan commitment, then the instance is a savings plan.
- If there is any free compute service plan commitment, then the instance is a savings plan.
- Otherwise, the instance will run as a full-price on-demand instance.
Throughout the lifetime of an instance, it can change its “price” whenever there’s any change in the commitment utilization rate. For example, if an instance is running as a full price on-demand instance, and another instance that was utilizing a compute savings plan commitment was terminated, the first instance will start utilizing this commitment if its hourly price rate has enough free space under this commitment. It might take a couple of minutes for this change to show, but since the billing is being calculated retroactively, in practice it’s starting to utilize the commitment right away.
AWS: How can I update the instance metadata (IMDS) in my cluster?
Instance metadata service (IMDS) is data about your instance that you can use to configure or manage the running instance or virtual machines. IMDS comes from the cloud providers. The metadata can include instance ID, IP address, security groups, and other configuration details.
Instance metadata service version 2 (IMDSv2) addresses security concerns and vulnerabilities from IMDSv1. IMDSv2 has more security measures to protect against potential exploitation and unauthorized access to instance metadata.
Scenario 1: Ocean and Elastigroup
You can define metadata for autoscaling groups in AWS that gets imported when you import the groups from AWS to Spot. You can manually configure them in Spot to use IMDSv2.
-
Follow the Ocean AWS Cluster Create or Elastigroup AWS Create API instructions and add this configuration for the cluster:
"compute": {
"launchSpecification": {
"instanceMetadataOptions": {
"httpTokens": "required",
"httpPutResponseHopLimit": 12,
"httpEndpoint": "enabled"
}
}
} -
Apply these changes to the currently running instances so the clusters are restarted and have the new definitions:
Scenario 2: Stateful Node
When a stateful managed node is imported from AWS, Spot creates an image from the snapshot. When an instance is recycled, the metadata configuration is deleted and changes to IMDSv1.
You can use your own AMI and configure IMDSv2 on it. All instances launched after recycling will have IMDSv2 by default.
-
Configure IMDSv2 on your AMI:
-
If you're creating a new AMI, you can add IMDSv2 support using AWS CLI:
aws ec2 register-image Let me know if there is anything else I can help you with.
--name my-image \
--root-device-name /dev/xvda \
--block-device-mappings DeviceName=/dev/xvda,Ebs={SnapshotId=snap-0123456789example} \
--imds-support v2.0 -
If you use an existing AMI, you can add IMDSv2 using AWS CLI:
aws ec2 modify-image-attribute \
--image-id ami-0123456789example \
--imds-support v2.0
-
-
In the Spot console, create a stateful node with the custom AMI.
AWS: Are stateful node resources deallocated when I delete an instance?
When you delete a stateful node, you can choose what gets deallocated using:
AWS: Can I convert a stateful node to a stateful Elastigroup?
You can reimport the stateful instance to Elastigroup:
-
In the Spot console, go to Elastigroup > Stateful Nodes, select the stateful node, and click Actions > Edit Configuration.
-
Go to Review > JSON and select Edit Mode.
-
Change lifeCycle to on_demand and click Update. For example:
"strategy": {
"lifeCycle": "on_demand”, -
Recycle the stateful node to launch an on-demand instance.
-
Wait until the new on-demand instance is running and healthy in the Spot console.
-
When you delete the stateful node, select Terminate VM no.
-
Make sure the stateful node is not running in the Spot console.
-
In the AWS console, make sure the stateful node instance is running.
-
In the Spot console, import a stateful node.
AWS: What happens if an elastic network interface (ENI) is deleted?
When an elastic network interface (ENI) is deleted, the stateful node tries to create a new ENI. If the stateful node can’t create a new ENI for the specific free IP, you will get a message that the ENI doesn’t exist. Elastigroup rolls back the node to a paused state.
When the IP is in use, the node is rolled back. You can see more information in the Spot console. Go to Elastigroup > Stateful Nodes and select the node. In the node:
- You can see a message with the details.
- On the Log tab, you can see an entry with the details.
AWS: What happens if a node has IP persistence and its security groups are updated?
If a stateful node has IP persistence, the persistent elastic network interface (ENI) is set with the node’s current security groups. When the node resumes:
- If the ENI has security groups that aren’t in the node, the security nodes are removed from the ENI.
- If the group has security groups that aren’t in the ENI, the security nodes are added to the ENI.
AWS: Can I use a public IP if the node has private IP persistence?
Depending on your setup, you can assign a public IP:
-
If the instance has Elastic IP, you can assign a public IP after it is launched.
-
You can assign a public IP before launching an instance, or set up the subnet for automatically assigning public IPs when launching a new instance.
-
If the instance has private IP persistence, you need to:
- In the AWS console, enable auto-assign IPv4.
- In the Spot console, pause the stateful node.
- Edit the stateful node > Advanced > Public IP Assignment and select According to subnet default or Associate public IP.
- In the AWS console, delete the ENI.
- In the Spot console, resume the stateful node. This will create a new ENI with the private IP from the IP pool and assign it with a public IP according to the subnet settings.
AWS: Can I use a static hostname?
Normally, AWS automatically sets the hostname when the instance is launched. It’s based on the instance’s private IPv4 address.
You can set a custom hostname that will continue to be used during the recycle process:
-
Edit the hosts file and change the name permanently:
sudo gedit /etc/hostname /etc/hosts -
Update the CUSTOM_HOSTNAME:
#!/bin/bash
CUSTOM_HOSTNAME="my-custom-hostname"
echo "preserve_hostname: true" > /etc/cloud/cloud.cfg.d/99_persist_hostname.cfg
echo "$CUSTOM_HOSTNAME" > /etc/hostname
sed -i "s/^127\.0\.0\.1.*/127.0.0.1 localhost $CUSTOM_HOSTNAME/" /etc/hosts
hostnamectl set-hostname "$CUSTOM_HOSTNAME"If you want to use the instance IPv4 address that the node was originally launched with:
-
In the metadata file, get the instance IP:
curl -s http://169.254.169.254/latest/meta-data/local-ipv4 -
Make sure Persist Private IP is configured. The custom hostname should also persist during replacement because the hostname is connected to the persistent IP.
- Go to the stateful node in the Spot console and click Actions > Edit Configuration.
- Click Persistent Resources > Network.
- Select Persist Private IP and enter the IP address.
-
In the user data, update the script:
-
Go to the stateful node in the Spot console and click Actions > Edit Configuration > Initialization and Termination.
-
Add this script to User Data:
#!/bin/bash
PRIVATE_IP=$(curl -s http://169.254.169.254/latest/meta-data/local-ipv4)
AWS_HOSTNAME="ip-$(echo $PRIVATE_IP | tr '.' '-')"
echo "preserve_hostname: true" > /etc/cloud/cloud.cfg.d/99_persist_hostname.cfg
echo "$AWS_HOSTNAME" > /etc/hostname
sed -i "s/^127\.0\.0\.1.*/127.0.0.1 localhost ${AWS_HOSTNAME}/" /etc/hosts
hostnamectl set-hostname "$AWS_HOSTNAME"
-
You can also persist the hostname for RHEL 7, 8, and 9, and CentOS 7, 8, and 9.
AWS: Why am I getting an Instance have been detected as stopped error?
You can see this error in the log:
WARN, Instance: [i-01234567890abcdefg] have been detected as Stopped.
It's possible to stop an instance in AWS, but Spot doesn't support the Stop action. This causes out-of-sync issues.
Restart the instance in AWS, then the Elastigroup will sync again. Use Pause/Resume instead of Stop.
AWS: Why am I getting a botocore.exceptions.ClientError error?
You may get this error:
botocore.exceptions.ClientError: An error occurred (UnsupportedOperation) when calling the StopInstances operation: You can't stop the Spot Instance {Instance-ID} because it is associated with a one-time Spot Instance request. You can only stop Spot Instances associated with persistent Spot Instance requests.
It's possible to stop an instance in AWS, but Spot doesn't support the Stop action.
AWS: Why am I getting a Volume of size (InvalidBlockDeviceMapping) error?
You get this message:
ERROR, Can't Spin Spot Instances: Code: InvalidBlockDeviceMapping, Message: Volume of size xx GB is smaller than snapshot 'snap-xxx', expect size >= xx GB"
If the current volume size is updated, it can cause a mismatch between the volume size and the AMI snapshot size.
Update the block device mapping configuration and increase the volume size to match the AMI snapshot size:
-
In the stateful node, go to Actions > Edit Configuration > Review > JSON > Edit Mode.
-
Update the group configuration and click Update.
"blockDeviceMappings": [
{
"deviceName": "/dev/sda1",
"ebs": {
"deleteOnTermination": false,
"volumeSize": 1500,
"volumeType": "GP2"
}
}
] -
Start a resume action.
AWS: Why am I getting a No data to display message in the stateful node > Monitoring > Memory Utilization?
Memory utilization graphs require the CloudWatch agent. If you don’t have CloudWatch set up, you’ll get a message in the Spot console when you try to view the memory utilization for a stateful node.
You can set up CloudWatch agent and then create or import a stateful node.
AWS: Can I delete a stateful node from Spot and manage it in AWS?
You can remove your stateful instance from Elastigroup and manage it only in AWS:
-
In the Spot console, go to Elastigroup > Stateful Nodes and select the stateful node.
-
Click Actions > Edit Configuration > Review > JSON > Edit Mode.
-
Change lifeCycle to on_demand and click Update. For example:
"strategy": {
"lifeCycle": "on_demand", -
Select the stateful node and click Actions > Recycle. This will launch an on-demand node.
-
Once the new on-demand instance is running, select the stateful node.
-
Click Actions > Edit Configuration.
-
Go to the Review tab > JSON > Edit Mode.
-
Use the API to delete the stateful node. Make sure to change shouldTerminateInstance to false if you want to keep the instance.
noteIf you don’t select false, the instance will be terminated, and the node will be deleted.
Azure: Can I increase RAM or CPU for osDisk and dataDisk on a stateful node?
Yes, you can update the RAM and CPU for an osDisk and dataDisk on a stateful node:
CPU
You can change the osDisk size and dataDisk size used to launch VMs with this API call: https://spec.dev.spot.io/#tag/Elastigroup-Azure-Stateful/operation/azureStatefulNodeUpdate.
You can also update the osDisk and dataDisk size in the stateful node’s JSON. Go to Edit Node > Review > JSON.
RAM size
You can only update the RAM size in the Azure portal or change the VM sizes in your configuration to have a higher RAM:
Azure: Can I increase the disk size for stateful nodes?
Yes, you can increase the disk size for stateful nodes.
-
If you have reattach persistance for OS disk:
- Pause the stateful node in the Spot console.
- Once the stateful node is paused, open the Azure Portal and click Disks.
- Click Custom Disk Size, update the disk size, and save the changes.
- Change the Performance Tier.
- Resume the stateful node in the Spot console.
-
If you have on-launch OS disk persistance:
- In the Azure portal, take a snapshot of the OS disk running the stateful node (VM).
- Create a new disk from the snapshot and change the disk size.
- You might also need to change the performance tier.
- In the Spot console, pause the stateful node.
- Go to Actions > Swap OS Disk.
- Select the Resource Group and New Disk Name, and click Update & Resume.
Azure: Can I delete an Azure stateful node and manage it in the Azure console?
-
Go to the stateful node in the Spot console and click Actions > Edit Configuration.
-
Go to Review, switch to JSON review, and select Edit Mode.
-
Change
revertToSpotto never:{
"statefulNode": {
"name": "Spot Stateful Node",
"region": "westus2",
"resourceGroupName": "spotResourceGroup",
"description": "This is my example stateful node",
"strategy": {
"fallbackToOd": true,
"drainingTimeout": 120,
"preferredLifecycle": "od",
"revertToSpot": "never",
"optimizationWindows": null, -
Add the
"preferredLifecycle": "od",parameter:{
"statefulNode": {
"name": "Spot Stateful Node",
"region": "westus2",
"resourceGroupName": "spotResourceGroup",
"description": "This is my example stateful node",
"strategy": {
"fallbackToOd": true,
"drainingTimeout": 120,
"preferredLifecycle": "od",
"revertToSpot": "never",
"optimizationWindows": null, -
Make sure the stateful node is not running on the Spot VM.
-
Go to Edit Node and delete the node.
-
In the Delete Stateful Node window, make sure to deselect all the options because you need the VM to run on the Azure side.
-
Verify that the VM with the resources is running in Azure.
Azure: Can I move stateful node resources to a new Azure subscription?
You can change your existing subscription and move the resources to a new Azure subscription:
-
Deallocate the running VMs:
-
Go to the stateful node in the Spot console and click Actions > Edit Configuration.
-
Go to Review, switch to JSON review, and select Edit Mode.
-
Change
revertToSpotto never:{
"statefulNode": {
"name": "Spot Stateful Node",
"region": "westus2",
"resourceGroupName": "spotResourceGroup",
"description": "This is my example stateful node",
"strategy": {
"fallbackToOd": true,
"drainingTimeout": 120,
"preferredLifecycle": "od",
"revertToSpot": "never",
"optimizationWindows": null, -
Add the
"preferredLifecycle": "od",parameter:{
"statefulNode": {
"name": "Spot Stateful Node",
"region": "westus2",
"resourceGroupName": "spotResourceGroup",
"description": "This is my example stateful node",
"strategy": {
"fallbackToOd": true,
"drainingTimeout": 120,
"preferredLifecycle": "od",
"revertToSpot": "never",
"optimizationWindows": null, -
Make sure the stateful node is not running on the Spot VM.
-
Go to Edit Node and delete the node.
-
In the Delete Stateful Node window, make sure to deselect all the options because you need the VM to run on the Azure side.
-
Verify that the VM with the resources is running in Azure.
-
Azure: Why isn’t my VM booting after recycling?
If the VM agent isn’t ready after recycling, it could be because the VM device name changed.
If you’re using a Linux storage device driver with several devices, the driver assigns major and minor numbers from the availability range to the device.
You should troubleshoot Linux VM device name changes. For example, you can use device names that persist when rebooting:
- Filesystem label
- UUID
- Derived device path
Azure: Why are my stateful nodes not importing/launching (LRS/ZRS)?
If your stateful nodes aren’t importing or launching, check the disk type and zone. If your disk type (storageAccountType) is:
- Locally redundant storage (standard_LRS or premium_LRS), you must have a zone defined (it can’t be null).
- Zone redundant storage for managed disks (standard_ZRS or premium_ZRS), the zone can be null.
If you want to use a regional disk (zone = null), you need to use ZRS disks.
Azure: Why is my on-demand instance reverting to spot outside of my configured hours?
Let’s say you want your on-demand instances to revert to spot instances daily, Monday through Friday, between 9 AM and 8 PM. You need to set your optimization hours for each day between those hours. For example:
-
In the Spot console, go to Elastigroup > Stateful Nodes and select the node.
-
Click Actions > Edit Configuration.
-
Go to Compute > Availability Settings.
-
In Continuous Optimization > Custom, you need to set the timeframe for each day. For example, if you want your on-demand instances to revert to spot instances daily, Monday through Friday, between 9 AM and 8 PM, you need to select:
- From: Monday, start time: 09:00, to: Monday, end time: 20:00.
- From: Tuesday, start time: 09:00, to: Tuesday, end time: 20:00.
- From: Wednesday, start time: 09:00, to: Wednesday, end time: 20:00.
- From: Thursday, start time: 09:00, to: Thursday, end time: 20:00.
- From: Friday, start time: 09:00, to: Friday, end time: 20:00.
Keep in mind, if you select From: Monday, start time: 09:00, to: Friday, end time: 20:00, it will set the entire time between Monday at 9 AM all the way through Friday at 8 PM, not daily between 9 AM and 8 PM. This means that your on-demand instances can revert to spot instances past 8 PM on Mondays, Tuesdays, Wednesdays, and Thursdays.