Ocean and Ocean for Apache Spark FAQs
Ocean
AWS, Azure, GCP: What regions does Spot support for my cloud provider?
AWS Regions
us-east-1, us-east-2, us-west-1, us-west-2, ca-central-1, sa-east-1, eu-central-1, eu-west-1, eu-west-2, eu-west-3, eu-north-1, ap-south-1, me-south-1, ap-southeast-1, ap-southeast-2, ap-northeast-1, ap-northeast-2, ap-east-1, cn-north-1, cn-northwest-1, ap-northeast-3, af-south-1, eu-south-1, us-gov-east-1, us-gov-west-1, cn-north-1, cn-northwest-1.
Azure Regions
australia-central, australia-central-2, australia-east, australia-south-east, brazil-south, canada-central, canada-east, central-india, central-us, east-asia, east-us, east-us-2, france-central, france-south, germany-central, germany-north, germany-north-east, germany-west-central, japan-east, japan-west, korea-central, korea-south, north-central-us, north-europe, norway-east, norway-west, south-africa-north, south-africa-west, south-central-us, south-east-asia, south-india, switzerland-north, switzerland-west, uae-central, uae-north, uk-south, uk-west, west-central-us, west-europe, west-india, us-gov-arizona, us-gov-texas, us-gov-virginia, west-us, west-us-2, west-us-3.
GCP Regions
us-east1, us-east1, us-east1, us-east4, us-east4, us-east4, us-central1, us-central1, us-central1, us-central1, us-west1, us-west1, us-west1, europe-west4, europe-west4, europe-west4, europe-west1, europe-west1, europe-west1, europe-west3, europe-west3, europe-west3, europe-west2, europe-west2, europe-west2, asia-east1, asia-east1, asia-east1, asia-southeast1, asia-southeast1, asia-southeast1, asia-northeast1, asia-northeast1, asia-northeast1, asia-south1, asia-south1, asia-south1, australia-southeast1, australia-southeast1, australia-southeast1, southamerica-east1, southamerica-east1, southamerica-east1, asia-east2, asia-east2, asia-east2, asia-northeast2, asia-northeast2, asia-northeast2, europe-north1, europe-north1, europe-north1, europe-west6, europe-west6, europe-west6, northamerica-northeast1, northamerica-northeast1, northamerica-northeast1, us-west2, us-west2, us-west2.
AWS: How do virtual node group-level and cluster-level shutdown hours work?
When shutdown hours end and Ocean needs to launch a node, it searches for a virtual node group with these characteristics:
- It is not in shutdown hours.
- Has no taints (Ocean will not launch a virtual node group that has a taint).
maxInstanceCount > 0(or not set).
Ocean sorts the groups as follows:
- Highest max instance count.
- Highest spot percentage.
- Highest number of AZs.
- Highest number of possible instance types defined.
Virtual Node Group shutdown hours:
Unlike cluster-level, virtual node group-level has no “guaranteed” scale-up to “wake up” the cluster.
Scale-up occurs only if no other node can run the controller, and one of the virtual node groups that can run the controller was recently in shutdown hours.
However, Ocean will not always scale up from a given virtual node group that was in shutdown hours. For example, if a virtual node group has a taint, Ocean will not launch a node from it when the shutdown hours end. Instead, Ocean applies cluster-level logic to find a suitable virtual node group to launch a node.
See also Set Shutdown Hours.
AWS, Azure, GCP: What's the difference between allocation and utilization for Ocean right sizing?
Estimating the proper amount of CPU and memory when assigning resource requests to workloads is a challenge that teams face when designing Kubernetes or ECS clusters. To address this challenge and create even more resource-efficient clusters, Ocean has implemented a right-sizing recommendation mechanism.
Right-sizing recommendations are provided per container and summarized for the entire workload for easy presentation at a high level. Recommendations per container enable you to easily understand exactly which applications require changes in resource requests and implement those changes quickly.
Applying the changes suggested by those notifications helps utilize resources in the cluster in a more precise manner and lowers the chances of cluster issues resulting from under- or over-utilization of resources.
Sometimes, there’s a difference between the number of resources in use in the Spot console and AWS.
Ocean performs scaling according to allocation. There are times when a pod’s request fully utilizes the number of resources allocated. Ocean’s scaling takes this into consideration. This is why a discrepancy may occur. The workload can use fewer resources than the number of resources that were initially allocated or requested.
Ocean’s solution to this mismatch is a feature called Right Sizing. The Right Sizing tab shows the discrepancy between the number of resources allocated (Requested) and the number of resources that are currently utilized (Recommended). This can help you make changes to your current resource utilization.
In the Recommendations table, you can see the exact amount of resources to change from the pod’s request.
AWS, Azure, GCP: Why is my instance in an unnamed virtual node group?
A node is running in an Ocean cluster and is an unnamed virtual node group.
This can happen if your visual node group was deleted in Terraform. When you delete a virtual node group in Terraform, the spotinst_ocean_aws_launch_spec > delete_nodes needs to be manually set to true in the Terraform resource. If it's not set to true, the node will keep running and not be in a virtual node group.
AWS, Azure, GCP: Why am I getting a snapshotId cannot be modified on the root device error?
If you get a snapshotId cannot be modified on the root device error:
-
In the Spot console, go to Ocean > Cloud Clusters, and select the cluster.
-
On the Virtual Nodes Groups tab, select the virtual node group.
-
Click JSON.
-
In the blockDeviceMappings, update the snapshotID or remove it:
"blockDeviceMappings": [
{
"deviceName": "/dev/xvda",
"ebs": {
"deleteOnTerminaspoton": true,
"encrypted": false,
"iops": 3000,
"throughput": 125,
"snapshotId": "snap-1234",
"volumeSize": 100,
"volumeType": "GP3"
}
}
] -
Click Save.
AWS, Azure, GCP: Can I set the spotPercentage on both a cluster and a virtual node group at the same time?
No, you will get this error:
Virtual Node Group configuration failed to update. Reason: Error while trying to create LaunchSpec. spotPercentage cannot be set on both ocean cluster and launch spec
The parameter spotPercentage cannot be used for both a cluster and one of its virtual node groups at the same time. This is intentional. Either remove it from the cluster or from the virtual node group.
AWS, Azure, GCP: Why can’t I spin new instances (duplicate tags)?
You can get this message when the group or cluster is scaling up instances:
Can't Spin Instances: Code: ValidationError, Message: can't spin spot due to duplicate tags error
This happens if you have duplicate tags configured:
- The cluster has more than one of the same custom tags.
- You created a custom tag key with spotinst—Spot automatically creates scaling tags that start with spotinst, resulting in multiple identical tags.
AWS, GCP: Can I log events for the Spotinst SDK for Python?
You can get a detailed response for the Python SDK. For example, you can include request IDs and times.
Add the log_level to your scripts: client = session.client("elastigroup_aws", log_level="debug").
Change the session client from elastigroup_aws to the client you need.
AWS: What is the default draining timeout?
Draining timeout is the time in seconds to allow the instance or node to be drained before terminating it.
The default draining for:
- Elastigroup is 120 seconds
- Ocean is 300 seconds
- ECS (Elastigroup/Ocean) is 900 seconds
AWS: What are the minimum permissions Spot needs to my AWS environment?
You can see the list of permissions required for Spot in Sample AWS policies.
AWS: Can Elasticsearch integrate with Spot?
You can stream Elastigroup logs to an AWS S3 bucket. Then, you can configure Elasticsearch and Kibana to collect logs from the S3 bucket:
-
Elastigroup add this code to the JSON:
"logging": {
"export": {
"s3": {
"id": "di-123"
}
}
}
AWS: Can I set up gp3 volumes in Ocean?
You can change your volume type to gp3 by:
-
Adding a block device mapping for a single virtual node group in the Spot console:
- In the Spot console, go to Ocean > Cloud Clusters and select the cluster.
- On the Virtual Nodes Groups tab, select the virtual node group.
- Go to Advanced > Block Device Mapping.
- Add the block device mapping and click Save.
- Roll the virtual node group if you want the changes to apply immediately on new nodes.
-
Changing the AMI to an AMI with gp3 volume type:
- In the Spot console, go to Ocean > Cloud Clusters and select the cluster.
- On the Virtual Nodes Groups tab, select the virtual node group.
- Go to Advanced > Image.
- Select an AMI with gp3.
-
Making the default virtual node group gp3 by adding a block device mapping at the cluster level.
-
Add the block device mapping:
- In the JSON: select the cluster > Actions > Edit Cluster > Review > JSON > Edit Mode.
- Using the Ocean AWS cluster update API.
Keep in mind, you cannot use both block device mapping and root volume size at the same time.
Sample block device mapping:
{
"group": {
"compute": {
"launchSpecification": {
"blockDeviceMappings": [
{
"deviceName": "/dev/sda1",
"ebs": {
"deleteOnTermination": true,
"volumeSize": 24,
"volumeType": "gp2"
}
}
]
}
}
}
}- Make sure to roll the cluster to replace the current instance gracefully with the changes.
-
AWS: Why do some on-demand instances in my AWS account use reservations or savings plans with utilizeCommitments: false?
You can have on-demand instances running in your group/cluster using reserved instance/savings plan even if you have set utilizeCommitments: false.
This happens because of:
-
AWS commitments coverage: When an on-demand instance launches in AWS, if there are any existing reservation or savings plan AWS may use them. AWS has its own way of deciding if an instance can be covered by a commitment plan. If the instance meets certain criteria, it will be covered if there's available space. This is how AWS handles reservations and savings plans. This happens even if you select utilizeCommitments: false.
-
Elastigroup/Ocean’s explicit commitment utilization: If you’ve selected utilizeCommitments: true, Spot imitates AWS’s method to help you utilize all the commitment plans for your AWS account. If there is free space in the commitment plan and markets, your on-demand instances run reserved instances/savings plans.
An on-demand instance marked as a reserved instance/savings plan doesn't always mean it will launch as a commitment plan. There can be other reasons for launching on-demand instances, such as when there is no spot capacity available or when certain requirements in Ocean need an on-demand instance. Then, if the on-demand instance is eligible, it will automatically use a commitment plan if there's space.
Spot cannot control how AWS automatically handles commitment plan utilization. In addition, Spot cannot prioritize which on-demand instances should be on a commitment plan and which should not.
AWS: What’s the difference between lifecycle OD(SP) and lifecycle OD(RI)?
- OD(SP) is an on-demand instance with a savings plan. An OD(SP) is an on-demand instance that utilizes a savings plan (SP) commitment. Savings plans have a flexible pricing model that offers significant savings on AWS usage, in exchange for a commitment to use a specific amount of resources over a one- or three-year term. The utilization of a Savings Plan is determined by AWS, based on available commitments.
- OD(RI) is an on-demand instance with a reserved instance. An OD(RI) is an on-demand instance that utilizes a reserved instance (RI) commitment. Reserved instances give a billing discount applied to the use of on-demand instances in your account. Like savings plans, reserved instances require a commitment to use a specific instance type in a specific region for a one- or three-year term. AWS automatically applies the reserved instance discount to eligible instances based on the availability of the reserved instance commitment.
AWS: Why is my on-demand instance utilized as a reserved instance/savings plan?
When is an on-demand (OD) instance a reserved instance (RI), savings plan (SP), or full-priced on demand?
When launching an on-demand instance, you cannot specifically request it to run as a reserved instance or savings plan.
AWS decides according to:
- If the market matches a free zonal reserved instance commitment, then the instance is a reserved instance.
- If the market matches a free regional reserved instance commitment, then the instance is a reserved instance.
- If the market matches a free EC2 instance savings plan commitment, then the instance is a savings plan.
- If there is any free compute service plan commitment, then the instance is a savings plan.
- Otherwise, the instance will run as a full-price on-demand instance.
Throughout the lifetime of an instance, it can change its “price” whenever there’s any change in the commitments utilization rate. For example, if an instance is running as a full price on-demand instance, and another instance that was utilizing a compute savings plan commitment was terminated, the first instance will start utilizing this commitment if its hourly price rate has enough free space under this commitment. It might take a couple of minutes for this change to show, but since the billing is being calculated retroactively, in practice it’s starting to utilize the commitment right away.
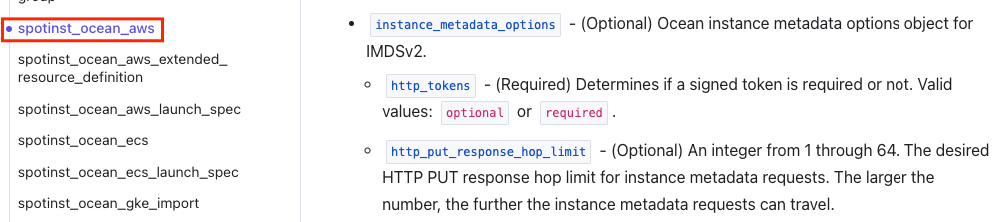
AWS: How do I enable access to the instance metadata tags on the cluster and virtual node group levels?
See this AWS guide for an overview of working with the Instance Metadata Service (IMDS) and instance tags in the instance metadata.
You can enable access to clusters and virtual node groups via Terraform or the Spot API.
To enable access to your cluster via Terraform, refer to the AWS documentation and the following screenshots:

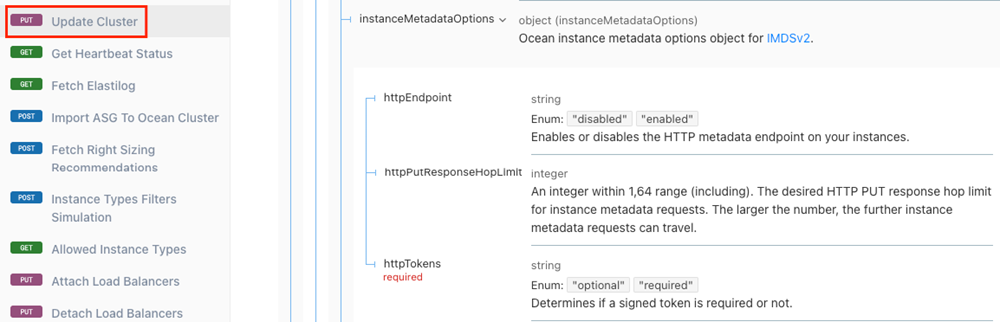
To enable access to your cluster via API, refer to the Spot API (Update Cluster) and the following screenshots:
To enable access to your virtual node groups via Terraform, refer to the AWS documentation and the following screenshots:
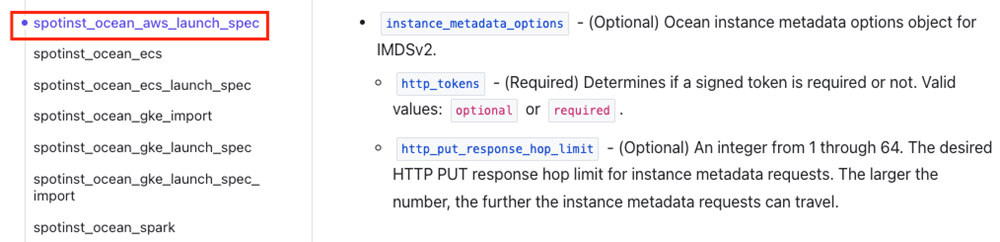

To enable access to your virtual node groups via API, refer to the Spot API (Update VNG) and the following screenshots:
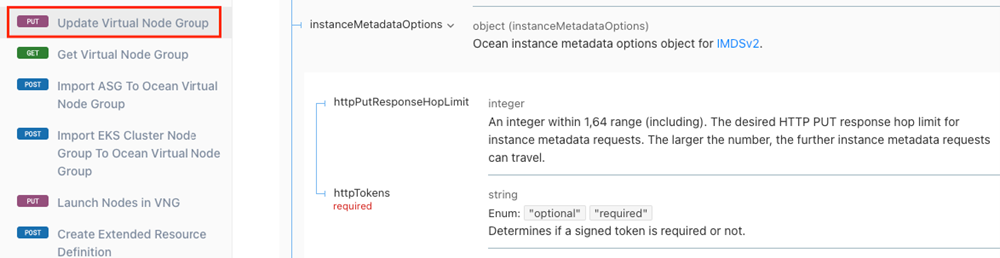
AWS: Does a cluster roll replace nodes containing pods with the spotinst.io/restrict-scale-down label?
Yes, a cluster roll will override the spotinst.io/restrict-scale-down label. Nodes containing pods with the spotinst.io/restrict-scale-down label will be replaced during a cluster roll.
Nodes can be replaced during a cluster roll even if the instance is locked. Instance lock only protects the instance from autoscaling actions. Cluster roll is a manually triggered action that requires replacing all the cluster’s instances.
AWS: How do I add Arm64 instance types to a virtual node group?
You may not be able to add/select any arm64 instance type(s) to a custom virtual node group, for one (or both) of the following reasons:
- The custom virtual node group does not have an arm64 supportive AMI.
- The cluster has a whitelist or blacklist in the cluster config, and does not support these instance types in the virtual node group.
If the AMI does not support arm64:
- Add an arm64 supportive AMI to the virtual node group.
- Select Arm64 instances in the virtual node group config.
If the cluster config has a whitelist or blacklist in the config:
- Include (whitelist) or exclude (blacklist) instance types as required.
- Add the required instances in the custom virtual node group.
AWS: Why can’t I see all my AWS IAM roles when setting up a cluster/group?
When you’re in a cluster or group, you only see roles associated with the instance profile.
AWS: How can I update the instance metadata (IMDS) in my cluster?
Instance metadata service (IMDS) is data about your instance that you can use to configure or manage the running instance or virtual machines. IMDS comes from the cloud providers. The metadata can include instance ID, IP address, security groups, and other configuration details. Instance metadata service version 2 (IMDSv2) addresses security concerns and vulnerabilities from IMDSv1. IMDSv2 has more security measures to protect against potential exploitation and unauthorized access to instance metadata.
Scenario 1: Ocean and Elastigroup
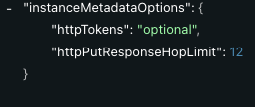
You can define metadata for autoscaling groups in AWS that gets imported when you import the groups from AWS to Spot. You can manually configure them in Spot to use IMDSv2.
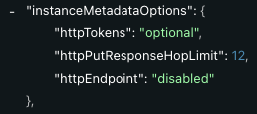
- Follow the Ocean AWS Cluster Create or Elastigroup AWS Create API instructions and add this configuration for the cluster:
"compute": {
"launchSpecification": {
"instanceMetadataOptions": {
"httpTokens": "required",
"httpPutResponseHopLimit": 12,
"httpEndpoint": "enabled"
}
}
}
- Apply these changes to the currently running instances so the clusters are restarted and have the new definitions:
Scenario 2: Stateful Node
When a stateful managed node is imported from AWS, Spot creates an image from the snapshot. When an instance is recycled, the metadata configuration is deleted and changes to IMDSv1.
You can use your own AMI and configure IMDSv2 on it. All instances launched after recycling will have IMDSv2 by default.
-
Configure IMDSv2 on your AMI:
- If you're creating a new AMI, you can add IMDSv2 support using AWS CLI:
aws ec2 register-image \
--name my-image \
--root-device-name /dev/xvda \
--block-device-mappings DeviceName=/dev/xvda,Ebs={SnapshotId=snap-0123456789example} \
--imds-support v2.0- If you use an existing AMI, you can add IMDSv2 using AWS CLI:
aws ec2 modify-image-attribute \
--image-id ami-0123456789example \
--imds-support v2.0 -
In the Spot console, create a stateful node with the custom AMI.
AWS: What does autoTag in CloudFormation do?
When you use autoTag in CloudFormation, Spot adds these tracking tags to instances provisioned as part of the custom resource:
-
spotinst:aws:cloudformation:logical-id -
spotinst:aws:cloudformation:stack-name -
spotinst:aws:cloudformation:stack-idYou can see examples of autotagging in:
AWS: How can I utilize Cilium in Ocean Kubernetes clusters?
See the following topic:
AWS: Why doesn’t Spot gracefully terminate instances if AWS gives a 2-minute termination notice?
AWS has a 2-minute warning before terminating spot instances. In reality, the warning doesn’t always give you the full 2 minutes. Sometimes, it can be as short as a few seconds.
When AWS terminates an instance, the machine status is updated regardless of the notification. Elastigroup and Ocean monitor the instance's status and can immediately launch a replacement spot instance. For this to happen, capacity must be available in the AWS market. Spot can’t always run the shutdown script in time due to capacity.
You can get higher availability by including:
- More instance types and availability zones for the group/cluster
- Fallback to on-demand
AWS: What happens if I change the spotPercentage to 0?
If you change the Spot % to 0, your already running spot instances do not automatically change to on-demand in a cluster/group.
You need to:
-
The automatic process only happens when changing the Spot % from on-demand instances to spot (fix strategy in Elastigroup, Ocean).
AWS: Why is EBS optimization disabled on instances optimized by default?
Amazon EBS–optimized instances use an optimized configuration stack and provide additional, dedicated bandwidth for Amazon EBS I/O.
Instances that are EBS-optimized by default are optimized regardless of the parameter settings. There is no need to enable EBS optimization and no effect if you disable EBS optimization in AWS or in Spot.
If an instance type isn’t EBS-optimized by default, you can enable optimization:
- In the Spot console, go to the Ocean cluster or Elastigroup.
- Click Compute > launchSpecification.
- Set ebsOptimized to true.
AWS: Why can’t I spin new instances (tag policies)?
If you’re getting this message:
Can't Spin Spot Instances: Message: The tag policy does not allow the specified value for the following tag key: 'XXX'.
It means a tag defined in your Elastigroup or cluster doesn’t comply with AWS’s tag policy.
-
In the Spot console, go to:
- Elastigroup > Groups > click on the Elastigroup > Log.
- Ocean > Cloud Clusters > click on the cluster > Log.
-
Identify the problematic tag keys/values.
-
Review AWS’s tag policies and how to set up tag policies.
-
In the Spot console, update the tag keys/values:
- Elastigroup > Groups > click on the Elastigroup > Actions > Edit Configuration > Compute > Advanced Settings.
- Ocean > Cloud Clusters > click on the cluster > Actions > Edit Cluster > Compute.
The instance will be launched when the tags in Spot clusters/groups comply with the tag policy defined in AWS.
AWS: Why can’t I spin new instances (encoded authorization)?
You can get these messages when the group or cluster is scaling up instances:
-
Can’t Spin Instances: Message: You are not authorized to perform this operation. Encoded authorization failure message -
Can’t Spin On-Demand Instances: Message: You are not authorized to perform this operation. Encoded authorization failure messageThese messages could be related to service control policies (SCP). Keep in mind, Spot doesn’t get SCP information from AWS, so doesn’t know which instance types AWS blocks because of the SCP restrictions. As a result, Spot cannot launch a new instance of a different type.
-
You need to identify the reason for the error in AWS.
-
In the Spot console, update the instance types:
-
AWS: Why can’t I spin new instances (UnsupportedOperation)?
You can get this message when the group or cluster is scaling up instances:
Can't spin spot instance: Code: UnsupportedOperation, Message: The instance configuration for this AWS Marketplace product is not supported. Please see the AWS Marketplace site for more information about supported instance types, regions, and operating systems.
This typically happens if the group/cluster AMI product doesn’t support specific instance types in the group/cluster instance list.
-
Identify the AMI:
- Search AWS Marketplace for the AMI ID.
- Elastigroup: in the Spot console, go to Elastigroup > Groups > select the group > Group Information and click Details > productCodeId.
- Ocean: in the Spot console, go to Ocean > Cloud Clusters > select the cluster > Actions > Edit Cluster > Compute > Instance specifications > View AMI details > productCodeId.
-
Troubleshoot AWS Marketplace AMIs. For example, check the instance types, regions, and availability zones. You can compare the instance types in AWS with the Spot console:
- Elastigroup: in the Spot console, go to Elastigroup > Groups > select the group > Compute > Instance types.
- Ocean: in the Spot console, go to Ocean > Cloud Clusters > select the cluster > Actions > Edit Cluster > Compute > Instance types.
AWS: Why am I getting an exceeded the number of VPC security allowed per instance message?
You may get this message when creating or importing an Elastigroup or cluster if you reach your AWS service quota limit for security groups per network interface:
POST https://api.spotinst.io/aws/ec2/group?accountId=act-xxxxx: 400 (request: "xxxxx") SecurityGroupLimitExceeded: You have exceeded the number of VPC security groups allowed per instance.
You can request a quota increase from AWS.
AWS: Why am I getting a Scale down as part of instance recovery or Scale up as part of instance recovery message?
You can get this log message if:
-
The instance is scaled down because of AWS’s capacity.
-
An instance replacement was initiated because of AWS’s capacity. A new instance is launched to replace an instance that was taken back because of AWS’s capacity.
-
An instance is manually terminated in AWS.
This means that there are no spot markets available to launch spot instances. You can add more spot markets to improve availability:
-
For Elastigroup, instance types and availability zones.
-
For Ocean, instance types and availability zones.
AWS: Why am I getting a Can't Spin On-Demand Instances: Code: InvalidKeyPair.NotFound message?
You can get this message if the key pair is missing or not valid:
Can't Spin On-Demand Instances: Code: InvalidKeyPair.NotFound, Message: The key pair 'xxxxx' does not exist
Update the key pair:
- In the Spot console, go to Ocean > Cloud Clusters, and click on the name of a cluster.
- Click Actions > Edit Cluster > Compute.
- In Instance Specifications, select a Key Pair.
AWS: Why am I getting an InsufficientFreeAddressesInSubnet message?
This can happen if the subnet doesn’t have enough free IP addresses for your request. Free up IP addresses in this subnet.
AWS: Why can’t I connect to an instance in Spot using SSH?
It’s possible that you can connect to your AWS instance using SSH but not your Spot instance, even with the same VPC, subnet, security group, and AMI.
One of the reasons this can happen is if you’re using enhanced networking and aren’t using the default eth0 predictable network interface name. If your Linux distribution supports predictable network names, this could be a name like ens5. For more information, expand the RHEL, SUSE, and CentOS section in Enable enhanced networking on your instance.
Azure: Can I use SSH to connect to an Azure VM?
Azure: Why can my cluster not perform scaling actions (invalid client secret)?
You got this error in the logs, and it’s not possible for the cluster to perform any scaling actions:
Invalid client secret provided. Ensure the secret being sent in the request is the client secret value, not the client secret ID, for a secret added to app
In Azure Kubernetes Service (AKS), there are two kinds of secrets: client secret ID and client secret value.
Generate a new client secret value and update it in the API.
ECS, EKS, GKE: How does cooldown work in Ocean?
For scale-up events, Ocean scales up as quickly as possible.
For scale-down events, cooldown is the number of seconds that Ocean waits after the end of a scaling action before starting another scaling action. The default is 300 seconds (5 minutes).
Cooldown is set at the cluster level and is applied across all virtual node groups in the cluster. So if a node of one virtual node group is scaled down, then Ocean waits for the cooldown time to pass before scaling down another node in a virtual node group.
You can set the cooldown period:
-
In the Spot console, go to Ocean > Cloud Clusters > select the cluster > Actions > Edit Cluster > Review > JSON > Edit Mode.
-
Using the APIs:
ECS, EKS: Are new nodes launched in the same availability zone as the old nodes?
Cluster roll randomly chooses the nodes and divides the instances between batches according to the size of their resources. It doesn’t matter which availability zones the nodes are from.
ECS, EKS: How do I create spot interruption notifications?
You can use AWS EventBridge to send spot interruption warnings to the Spot platform in real time. These warnings are pushed by AWS at an account level and are region-specific. You'll need to set up notifications for each account and region.
-
In your AWS console for the EventBridge page, make sure the EventBridge status is Inactive.
-
Reestablish the connection:
- Open your AWS console and select the region.
- Go to the AWS CloudFormation service.
- Create a stack with new resources for a specific region, or create a StackSet for multiple regions.
- Select Create from an S3 URL and use this template URL:
https://spotinst*public.s3.amazonaws.com/assets/cloudformation/templates/spot*interruption*notification*event*bridge*template.json - Click Next.
- Fill in the stack name, Spot account ID, and Spot token, then click Next.
- Repeat for each active region.
ECS, EKS: Why can't I spin new spot instances (InsufficientInstanceCapacity)?
This message is shown in the console logs if Ocean attempts to scale up a certain spot instance type in a particular availability zone. This happens because of a lack of capacity on the AWS side.
Can't Spin Spot Instances: Code: InsufficientInstanceCapacity, Message: We currently do not have sufficient m5.2xlarge capacity in the Availability Zone you requested (us-east-1a). Our system will be working on provisioning additional capacity. You can currently get m5.2xlarge capacity by not specifying an Availability Zone in your request or choosing us-east-1b, us-east-1c, us-east-1d, us-east-1f.
Ocean is aware of a pending pod and is spinning up an instance. Based on your current instance market, Ocean chooses the instance type in a particular availability zone and attempts to scale up. If it fails due to a lack of capacity, the error message is shown in the console logs.
You can solve this by:
- Having many instance types, so Ocean can choose the best available markets.
- Having multiple availability zones to provide more availability.
- For workloads that are not resilient to disruptions, configure the on demand label
spotinst.io/node-lifecycle.
ECS, EKS: Why can't I spin new instances (InvalidSnapshot.NotFound)?
You have scaling up instances for your Elastigroup or Ocean clusters and you get this message:
ERROR, Can't Spin Instances: Code: InvalidSnapshot.NotFound, Message: The snapshot 'snap-xyz' does not exist.
If you have a block device that is mapped to a snapshot ID of an Elastigroup or Ocean cluster and the snapshot isn't available, you will get this error. This can happen if the snapshot is deleted.
If you have another snapshot, then you can use that snapshot ID for the block device mapping. If not, you can remove the snapshot ID, and then the instance is launched using the AMI information.
- Elastigroup: on the Elastigroup you want to change, open the creation wizard and update the snapshot ID.
- Ocean: on the virtual node group you want to change, update the snapshot ID.
ECS, EKS: Why can't I spin new spot instances (MaxSpotInstanceCountExceeded)?
You can get this message if AWS's spot service limit is reached:
Can't Spin Spot Instances:Code: MaxSpotInstanceCountExceeded, Message: Max spot instance count exceeded
You may also get an email from Spot: Spot Proactive Monitoring | Max Spot Instance Count Exceeded. This email includes instructions for opening a support request with AWS, such as the instance type and region that triggered the error.
You can read the AWS documentation on spot instance quotas.
ECS, EKS: Why am I getting an InvalidBlockDeviceMapping error?
You can get this error when the group's device name (for Block Device Mapping) and the AMI's device name do not match:
Can't Spin Spot Instance: Code: InvalidBlockDeviceMapping, Message: The device 'xvda' is used in more than one block-device mapping
- AMI - "deviceName": "xvda"
- Group's configuration - "deviceName": "/dev/xvda"
Change the device name from xvda to /dev/xvda on the group's side. In the stateful node, go to Actions > Edit Configuration > Review > JSON > Edit Mode. Change the device name from xvda to /dev/xvda and click Update.
ECS: Why am I getting an import Fargate services error?
When you import Fargate services with more than 5 security groups, you get an error:
Failed to import Fargate services into Ocean. Please verify Spot IAM policy has the right permissions and try again.
In Spot, you see this warning:
Fargate import failed for xxx-xxxxxx, due to Failed to import services, too many security groups. Import less services to this group (Group ID: xxxx-xxxxxx).
You can have up to 5 security groups in each service according to this article. This means that if more than 5 security groups are defined in one of the services, the import doesn’t succeed.
Check the Ocean log to see if you see the error too many security groups, as it will get the same error.
Reimport Fargate services with less than 5 security groups and choose only one service at a time to import it successfully.
ECS: Can I launch an instance with a specific launch specification or virtual node group?
Yes, you can launch an instance with a specific launch specification or virtual node group:
-
In the Spot console, go to Ocean > Cloud Clusters.
-
Click on the name of the cluster.
-
Go to Virtual Node Groups > Create VNG.
-
If you want to create a launch specification with custom attributes, in Node Selection, add attribute keys and values. For example, key: stack*, value: dev.
-
Add the custom attribute to the user data startup script:
echo ECS_INSTANCE_ATTRIBUTES='{"stack":"dev"}' >> /etc/ecs/ecs.config. -
Add the constraints to the task definition or service:
memberOf(attribute:stack==dev).
When a new instance is launched, it will be from the dedicated virtual node group.
ECS: Why are ECS instances launched separately for each task?
An ECS cluster launches an instance just for a single task, even when there is capacity on the nodes currently running in the cluster. This can happen if a task has placement constraints called distinctInstance, which causes each task in the group to run on its own instance.
You can define which container instances Amazon ECS uses for tasks. The placementConstraints may be defined in one of these actions CreateService, UpdateService, and/or RunTask.
ECS: Why is the out of strategy replacement getting canceled for standalone tasks?
If your virtual node group has more on-demand instances than defined, your extra instances are reverted to spot instances when they become available. This is called the fix strategy.
If you see this message in the log:
DEBUG, Replacement of type Out of strategy for instance i-xxx has been canceled. Reason for cancelation: Instance contains stand-alone tasks, and the group's configuration doesn't allow termination of stand-alone tasks.
It means that your strategy cannot be fixed and your spot instances cannot be reverted to spot instances. This is because you have standalone tasks in the instances, and the group's configuration can't stop standalone tasks. The autoscaler cannot scale down these instances.
Update the cluster in the API or in the cluster's JSON file to include "shouldScaleDownNonServiceTasks": true.
The standalone task and instance are terminated and are not redeployed because they weren't created as part of a service.
ECS: Why are my container instances unregistered?
Your container instances may be unregistered if the newly launched Ocean ECS container instance:
-
Has unregistered contain instance events
-
Doesn’t have a Container Instance ID
-
Is eventually scaled down
-
CPU and memory resource allocations are 0%
-
Status: Can’t determine
Your container instance must be registered with an ECS cluster. If the container instance isn't registered, its status is unhealthy. Registering a container instance with an ECS cluster means you are telling the ECS service that a specific EC2 instance is available to run containers. It also sends information to ECS about the EC2 instance, such as its IP address, the docker daemon endpoint.
If your container is unregistered, you should make sure:
-
User Data
- Go to the cluster in the Spot console and click Actions > Edit Configuration > Compute.
- Add this script to User Data, using your cluster name.
#!/bin/bash
echo ECS_CLUSTER="xxxxx" >> /etc/ecs/ecs.config -
AMI
ECS is optimized and Agent (similar to the controller in Kubernetes) is configured in the AMI.
-
Security group and specific ports
- Port 22 (SSH) is required if you want to connect to your container instances using Secure Shell (SSH) for troubleshooting or maintenance. It is not directly related to ECS cluster registration, but it's commonly included for administrative access to the instances.
- Port 2375 (TCP) is used for the ECS container agent to communicate with the ECS control plane. It allows the agent to register the container instance with the cluster, send heartbeats, and receive instructions for task placement and management.
- Port 2376 (TCP) is used for secure communication between the ECS container agent and the ECS control plane. It enables encrypted communication and is recommended for improved security when managing your ECS cluster.
-
IAM role
Configure an instance profile with relevant permissions.
-
IP
Make sure you configured Public IP according to subnet, and have NAT gateway. If you change the configuration in the virtual node group, such as tags/user data, it immediately overrides the cluster's configuration.
ECS: What happens if I run a non-service task in a cluster without enough resources?
A non-service task is a standalone task that isn't part of a service. It's typically used for batch processing or one-time jobs rather than continuous, long-running services. When an independent task runs in a cluster, and there aren't enough resources available, the task may fail to launch due to CPU or memory errors. This means that no service is continuously attempting to launch tasks to meet the required number of tasks. Instead, the task will be launched later when resources become available.
ECS: Can I enable on-demand lifecycle for Ocean ECS?
You can set on-demand instances using placement constraints.
ECS: Why is auto-assigned public IP disabled when a Fargate service is created by Spot?
Your Fargate cluster has auto-assigned public IP enabled. When Spot clones the Fargate services and runs them with the same VPC and subnet settings on EC2 spot instances, it creates a new Fargate service.
AWS prevents EC2 cluster services from auto-assigning public IP addresses. You can see this message: code='InvalidParameterException', message='Assign public IP is not supported for this launch type.'
As a result, the new instances have auto-assign public IP disabled.
ECS: Why can’t autoscaler find an applicable instance type to scale up (pending headroom task)?
Headroom can only be scheduled if there are enough instance types. If you’re using manual headroom and there aren’t enough instance types, you may get this message:
WARN, AutoScaler - Attempt Scale Up, Task service:spotinst-headroom-task-ols-e72002a2-4 is pending but could not find any applicable instance type to scale up in order to schedule the pending Task.
You can:
-
Add more instance types (bigger instance types) to the virtual node group, which gives Ocean more options to choose from. This can reduce your costs.
-
Decrease the Reserve, CPU, Memory:
- In the Spot console, go to Ocean > Cloud Clusters and select the cluster.
- On the Virtual Node Groups tab, click on the virtual node group.
- Go to Advanced > Headroom and update the Reserve, CPU, and/or Memory.
ECS: Why am I getting a message that the virtual node group’s architecture doesn’t match the virtual node group template filter?
You may get this message if you create a custom virtual node group and then change the AMI:
error: The Virtual Node Group’s architecture doesn’t match the Virtual Node Group Template filter.
This can happen if the new AMI architecture does not support the instance types set in the default virtual node group.
Create a custom virtual node group with the new AMI:
- In the Spot console, go to Ocean > Cloud Clusters, and select the cluster.
- On the Virtual Node Groups tab, click Create VNG > Go to vng template.
- Update the template virtual node group to include more instances and click Save.
- Go back to the new virtual node group and finish setting it up.
You can choose to just update the default virtual node group to include more instance types:
- In the Spot console, go to Ocean > Cloud Clusters, and select the cluster.
- On the Virtual Node Groups tab, click VNG Template > Edit Mode.
- Update the Instance Types and click Save.
ECS: Can hostPort cause underutilized nodes?
If a node only has one task running, then it causes the node to be underutilized. Underutilized nodes should be bin-packed together if there are no constraints in the task/service definition.
Example service:
"placementConstraints": [],
"placementStrategy": [],
The task definition doesn't have constraints to spread tasks across nodes.
"placementConstraints": [
{
"type": "memberOf",
"expression": "attribute:nd.type == default"
}
],
Check the portMappings: hostPort value in the task/service defintion.
Port mappings allow containers to access ports on the host container instances to send or receive traffic. This configuration can be found in the task definition. The hostPort value in port mapping is normally left blank or set to 0.
Example:
"portMappings": [
{
"protocol": "tcp",
"hostPort": 0,
"containerPort": 443
}
]
However, if the hostPort value equals the containerPort value, then each task needs its own container. Any pending tasks trigger a scale-up, and the number of launched instances is equal to the number of pending tasks. This leads to underutilized instances and higher costs.
You can have multiple containers defined in a single task definition. Check all the portMappings configurations for each container in the task definition.
ECS: Can I monitor detached instances using tags?
You can monitor your detached instances using tags. When an instance gets detached, Spot tags it with:
Key: spotinst:aws:ec2:state
Value: detached
For a spot instance, the spot request is tagged. For an on-demand instance, the instance is tagged.
ECS: How can I check the ECS agent logs? Can I push the agent logs to CloudWatch?
You can check the logs for ECS instances, for example, to see why an instance was unhealthy.
If the instance hasn’t been terminated yet, you can connect to the instance to view the agent logs.
You can also push the ECS agent logs to CloudWatch. This lets you check the agent logs even after the instance is replaced.
EKS: My console banner shows: (EC2) status: Healthy, (Kubernetes) status: Can't determine
In most cases, the “(EC2) status: Healthy” message in the console indicates that instances successfully launch and pass the EC2 health check. The “Kubernetes status: can't determine” message may indicate an issue relating to node registration on the Kubernetes cluster. For help, contact Spot Support.
EKS: How can I disconnect a cluster from Ocean?
You can safely disconnect Ocean from an existing EKS Cluster:
-
Increase the number of instances in the ASG attached to the EKS cluster. This way, the pods that run on the nodes managed by Spot will be able to reschedule on the new instances and avoid downtime.
-
In the Spot console, go to Ocean > Cloud Clusters, and select the cluster.
-
Click Actions > Edit Cluster.
-
On the Review tab, click JSON > Edit Mode.
-
Change capacity > Minimum, Maximum, and Target to 0.
The instances managed by Ocean will be detached and the pods will be rescheduled on the new instances launched by AWS ASG.
-
In the Spot console, go to Ocean > Cloud Clusters, and select the cluster.
-
Click Actions > Delete.
EKS: Why can’t I select my EKS cluster in the Ocean import cluster wizard?
Your EKS cluster may not be included in the list of clusters when you’re trying to import to Ocean. This can happen if there aren’t any node groups in the cluster.
Add a node group to your EKS cluster then import the cluster again.
EKS: How can I get the AMI ID for EKS-optimized Amazon Linux?
You can get the AMI ID using the AWS Systems Manager Parameter Store API.
EKS: Why are DaemonSet pods not scheduled on all nodes in the cluster?
Your DaemonSet pods are only scheduled on one specific virtual node group, not on all the nodes in a virtual node group in cluster.
This can happen if you use taints on your pods in virtual node groups. You can either use taints on all your pods, or not use taints. You can't mix pods with taints and without taints.
Update your tolerances in the DaemonSet YAML so you can schedule DaemonSet pods on the nodes in virtual node groups with taints.
For example, you can update your DaemonSet pod YAML to include:
spec:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "statefulset"
effect: "NoSchedule"
EKS: Can I set a maximum capacity per virtual node group using eksctl?
Yes, you can use autoScaler: resourceLimits: maxInstanceCount: 10 to set capacity using eksctl.
For example:
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: example
region: us-west-2
nodeGroups:
- name: ng1
spotOcean:
# ...
autoScaler:
resourceLimits:
maxInstanceCount: 10
# ...
EKS: Why are my EKS nodes unhealthy?
Kubernetes nodes in the cluster have Unhealthy status—the node has a Node Name but the Kubernetes status is Unhealthy.
You can debug unhealthy Kubernetes nodes:
- Check the nodes' status by running this command in CLI:
kubectl get nodesLook for nodes in a NotReady or Unknown state. This indicates that the nodes are unhealthy or experiencing issues. - Get detailed information about the problematic nodes by running the
kubectl describecommand:kubectl describe node <node-name>. Look for any error messages or warnings that can help identify the problem. Pay attention to resource allocation issues, network connectivity problems, or other relevant information. - Verify the health of cluster components such as the kubelet, kube-proxy, and container runtime (for example, Docker, containerd). Check your local logs and the status of these components to identify any errors or issues.
- Examine the resource utilization of your nodes, including CPU, memory, and disk usage. High resource utilization can lead to node instability or unresponsiveness. Use tools like Prometheus or Grafana to monitor resource metrics.
- Ensure that network connectivity is properly configured and functioning between the Kubernetes control plane and the nodes. Verify that nodes can reach each other and communicate with external services.
- Use the
kubectl get eventscommand to check for cluster-level events that might provide insights into the node health issues. Events often contain helpful information about the state of your cluster and its components. - Examine the logs of individual pods running on the problematic nodes. Logs can provide clues about any application-specific issues or errors that might be impacting node health. Use the
kubectl logscommand to retrieve pod logs. - Verify that the node configurations (for example, kubelet configuration, network settings) are correct and aligned with the cluster requirements.
- Ensure that the container runtime (such as Docker, containerd) is properly installed and functioning on the nodes. Check the runtime logs for any errors or warnings.
- If you think that a specific component is causing the node health issues, consider updating or reinstalling that component to resolve any known bugs or conflicts.
EKS: How do unhealthy replacements work during workload migration?
When you have a workload migration in progress, there may be unhealthy instances. They are not replaced until after the migration finishes. This happens because Ocean’s scaler does not handle replacements in the cluster during workload migration.
If there is no active migration, after the configured unhealthy duration ends (the default is 120 seconds), the unhealthy instances are terminated and immediately replaced with new ones.
EKS: Can I check Ocean EKS clusters' horizontal pod autoscaling (HPA) policy?
Ocean doesn't actually have a horizontal pod autoscaling (HPA) policy. The HPA is essentially operating on the Kubernetes side so Ocean itself doesn't have an HPA.
The cluster autoscaler only takes care of provisioning the required number of nodes.
Essentially, if the load increases on your cluster, then Kubernetes will create more replicas, and Ocean will launch nodes for the new pods. Kubernetes HPA will create pods and Ocean will launch new nodes for pods to be scheduled.
EKS: Can I deploy AWS node termination handler on Spot nodes?
AWS node termination handler is a DaemonSet pod that is deployed on each spot instance. It detects the instance termination notification signal so that there will be a graceful termination of any pod running on that node, drain from load balancers, and redeploy applications elsewhere in the cluster.
AWS node termination handler makes sure that the Kubernetes control plane responds as it should to events that can cause EC2 instances to become unavailable. Some reasons EC2 instances may become unavailable include:
- EC2 maintenance events
- EC2 spot interruptions
- ASG scale-in
- ASG AZ rebalance
- EC2 instance termination using the API or Console
If not handled, the application code may not stop gracefully, take longer to recover full availability, or accidentally schedule work to nodes going down.
The workflow of the node termination handler DaemonSet is:
- Identify that a spot instance is being reclaimed.
- Use the 2-minute notification window to prepare the node for graceful termination.
- Taint the node and cordon it off to prevent new pods from being placed.
- Drain connections on the running pods.
- Replace the pods on the remaining nodes to maintain the desired capacity.
Ocean does not conflict with aws-node-termination-handler. It is possible to install it, but using aws-node-termination-handler is not required. Ocean continuously analyzes how your containers use infrastructure, automatically scaling compute resources to maximize utilization and availability. Ocean ensures that the cluster resources are utilized and scales down underutilized nodes to optimize maximal cost.
EKS: Why are custom parameters in virtual node group null*?
The JSON for a virtual node group has all the parameters from the Ocean template/default virtual node group. Any items you haven’t defined yet have a value of null. This way, you can edit the existing parameters.
EKS: Can I debug the Python SDK?
You can update this line in the SDK to debug:
- Change
client = session.client("ocean_aws")toclient = session.client("ocean_aws", log_level="debug"). - Create or update the cluster again.
EKS: Why can’t I see EKS clusters in Ocean in the Spot console when I’m importing to Ocean?
When importing EKS clusters to Ocean in the Spot console, some of your clusters may not show in the list you can import from. Make sure:
-
The EKS cluster is in the region you’re trying to import from.
-
You have the correct permissions and the most current Spot policy.
-
The Kubernetes cluster has an EKS version that is supported by Amazon. Spot supports an EKS version two months after the Amazon EKS release date. A version is considered deprecated for Spot when Amazon ends standard support. A version is considered retired for Spot when Amazon ends extended support.
-
You have at least one node group in your EKS cluster. There don’t need to be any nodes running in the node group, just configured in the AWS console.
-
If you’re using ASG in your EKS cluster, you need to import the EKS cluster using the legacy design:
- In the Spot console, go to Ocean > Cloud Clusters > Create Cluster.
- Select Elastic Kubernetes Service (EKS) > Continue.
- Select Revert to legacy design.
- Import from Auto Scaling Group.
EKS: Why doesn’t Ocean launch a node automatically after shutdown hours end?
You may run into a case where Ocean doesn’t automatically launch a node after the shutdown hours end. You then need to manually launch a node and reinstall the controller pod after the shutdown hours.
This can happen because Ocean automatically scales down the entire cluster to 0 when the period of running time ends. During the off time, all nodes are down, and the Ocean controller is down and does not report information to the autoscaler.
When the off time ends, Ocean starts a single node from a virtual node group without taints. If all virtual node groups have taints, Ocean starts a node from the default virtual node group unless useAsTemplateOnly is defined, in which case no node is started.
You need to make sure the controller is running, possibly on a node that Ocean does not manage. Once the node launches and is registered to the Kubernetes cluster, the Ocean controller is scheduled.
EKS: Why did my node launch without a taint?
You can force nodes to scale up from a dedicated virtual node group using custom taints and tolerations or custom nodeSelector labels.
Keep in mind, if you add taints or labels on the pod, you need to add matching labels and toleration on the virtual node group in both Node Selection and in the User Data (startup script). This launches the nodes with the correct taint and your workloads are scheduled properly.
EKS: Why am I getting a controllerClusterID already being used by another Ocean cluster message?
A cluster identifier (controllerClusterID) can only be used on one Ocean cluster at a time. This can happen if you’re trying to set up Ocean Insights on an existing Ocean cluster, or if the cluster already has Ocean controller installed on it.
Ocean Insights is intended for unmanaged clusters.
EKS: Why am I getting a Maximum Pods configuration reached message?
If you get a Maximum Pods configuration reached message for a node in the console:
- It usually means that you reached the EKS maximum pod limit. For example, the EKS maximum pod limit for r4.large is 29.
You can increase the EKS maximum pods in AWS. You can see more information about the number of pods per EKS instance on Stack Overflow.
- If the node has fewer pods than the EKS maximum pod limit, then check if the max pods limit is set at the user data level in the Ocean configuration.
Increase this limit for the user data in Ocean:
- Go to the cluster in the Spot console and click Actions > Edit Configuration > Compute.
- In User Data (Startup Script), increase the max-pods limit.
- Now roll the cluster
If you continue to get this error, roll the cluster again and disable Respect Pod Disruption Budget (PDB). You can also manually terminate the node.
EKS: Why am I getting an Invalid IAMInstanceProfile error?
You may get an Invalid IAMInstanceProfile error when you're creating an Ocean cluster using Terraform. This can happen if you use IAMInstanceProfileName instead of IAMInstanceProfileARN.
If you want to use IAMInstanceProfileName in Terraform, set use_as_template_only to true.
Once the cluster is configured to use the default virtual node group as a template, IAMInstanceProfileName can be used instead of Invalid IAMInstanceProfile.
EKS: Why am I getting unregistered nodes and syntax error or unexpected EOF messages?
If you have unregistered nodes and are getting log messages such as:
/var/lib/cloud/instance/scripts/part-001: line 5: unexpected EOF while looking for matching `"'
/var/lib/cloud/instance/scripts/part-001: line 9: syntax error: unexpected end of file
Feb 01 14:03:05 cloud-init[2517]: util.py[WARNING]: Running module scripts-user (<module ‘cloudinit.config.cc_scripts_user' from '/usr/lib/python2.7/site-packages/cloudinit/config/cc_scripts_user.pyc'>) failed
Make sure:
- The parameters are configured correctly (such as labels, AMI, IP, user data).
- The user data script is executable and working properly.
EKS: Why am I getting a Failed to create pod sandbox message in Kubernetes (failed to assign an IP address to container)?
You may get this message in Kubernetes:
Failed to create pod sandbox: rpc error: code = Unknown desc =
failed to set up sandbox container "xxxxx"
network for pod "coreservice-xxxxx":
networkPlugin cni failed to set up pod "coreservice-xxxxx"
network: add cmd: failed to assign an IP address to container
Each node on Kubernetes has a different number of elastic network interfaces (ENI) available. For example, M5.Large can only have 29+2*31 ENIs.
You can create a script to dynamically calculate the --max-pods value based on the instance type and CNI version. For example:
CNI_VERSION=<such as 1.11.4-eksbuild.1> MAX_PODS=$(/etc/eks/max-pods-calculator.sh --instance-type-from-imds --cni-version $CNI_VERSION)
--instance-type-from-imds gets the instance type from the instance metadata service (IMDS).
--cni-version $CNI_VERSION specifies the CNI version.
If you don’t define a value for --max-pods in the user data startup script for a virtual node group, the default AWS value is 110.
Defining a static value for --max-pods in the user data startup script for a virtual node group can cause overutilization and underutilization issues.
EKS: How can I update Terraform provider to the latest version?
You can:
- Download the Spot provider plugin and update it.
- Update the plugin from Terraform.
GKE: How do zones and regions work with clusters?
In GKE, regional clusters replicate the cluster’s control plane and nodes in the region's zones. Using multiple regions and zones helps protect against unexpected failures. Workloads can be redirected to nodes in different zones.
In Spot, when you import a regional cluster, the cluster is not integrated with its existing node pools. The instances are registered to the cluster. Spot does not replicate the nodes in all the zones. It acts as a zonal cluster.
Keep in mind:
- The control planes are managed in GKE and are replicated when a regional cluster is selected. This gives you high reliability in the control planes.
- Ocean autoscaler chooses the best markets available for the pending pods. Ocean quickly launches instances in a different zone if there's a zonal outage.
GKE: Can I set up committed use discounts on virtual node groups?
You can set up committed use discounts (CUDs) for clusters in Ocean and groups in Elastigroup. It cannot be used for virtual node groups.
Set up committed use discounts for:
GKE: Are shutdown hours supported in shielded node clusters?
Shutdown hours are not supported for GKE clusters with shielded nodes. If you use shutdown hours with shielded nodes, make sure that the Ocean controller is available at the end of the off time by checking that it runs on a node that Ocean does not manage. This is because the controller is part of the node registration process and requires an available node to run on.
GKE: Why are my nodes unregistered?
Some of the common reasons your GKE nodes can be unregistered are if:
- You have shielded nodes. Shutdown hours are not supported for GKE clusters with shielded nodes. If you use shutdown hours with shielded nodes, make sure that the Ocean controller is available at the end of the off time by checking that it runs on a node that Ocean does not manage. This is because the controller is part of the node registration process and requires an available node to run on.
- The cluster is in a private network. You need to configure NAT gateway on the cluster in GKE so it’ll have access to the internet.
Make sure the cluster has external-nat and ONE_TO_ONE_NAT set:
- In the Spot console, go to Ocean > Cloud Clusters > select the cluster > Action > Edit Cluster > Review > JSON
- In the API
For example:
{
"compute": {
"networkInterfaces": [
{
"network": "networkname",
"accessConfigs": [
{
"name": "external-nat",
"type": "ONE_TO_ONE_NAT"
}
],
"aliasIpRanges": [
{
"ipCidrRange": "/24",
"subnetworkRangeName": "subnetworkRangeName"
}
],
"projectId": "projectId"
}
]
}
}
GKE: Can I migrate workloads?
You can migrate workloads for GKE:
- In the Spot console, create a virtual node group with labels that match your workload.
- In GKE, disable the autoscaler so GKE won’t launch nodes for the pending pod which should be scheduled in Ocean’s managed nodes.
- In GKE, resize the clusters to 0 to drain the nodes:
gcloud container clusters resize <cluster_name> --num-nodes=0 --region=<region/zone> --node-pool <node_pool_name>.
Ocean then detects the pending pods and launches virtual node groups for the nodes.
GKE: Why can’t I spin new instances (boot disk architecture)?
If Ocean isn’t launching a VM, you might get this log message:
Can’t Spin Instance: Name: sin-abcd. Code: Error, Message: Invalid resource usage: 'Requested boot disk architecture (X86_64) is not compatible with machine type architecture (ARM64).`
This can happen because Ocean doesn’t validate VM architecture for GCP. You can troubleshoot this error in GCP.
GKE: Why am I getting a zone_resource_pool_exhausted (scale up) error?
You may get this log message when a VM is trying to scale up or launch VMs:
Can't Spin Instance: Name: abcde. Code: ZONE_RESOURCE_POOL_EXHAUSTED_WITH_DETAILS, Message: The zone 123 does not have enough resources available to fulfill the request, '(resource type:compute)'.
This can happen if the specific VM family and size aren’t available for a certain zone at the moment. Elastigroup or Ocean will try to automatically spin up a different VM in a different zone to compensate.
GKE: Why am I getting a Failed to update the group (launchSpec) error?
If you update the Kubernetes version and pods launch with the old version, you may get these errors:
-
ERROR, Failed to update the launchSpec ols-f775236b with the latest changes in GKE cluster tagging-stg-eu1-1. Reason: Node pool tagging-stg-eu1-1-pool does not exist. -
ERROR, Failed to update the group with the latest changes in GKE cluster tagging-stg-eu1-1. Reason: Node pool tagging-stg-eu1-1-pool does not exist.
This can happen if the original node pool is deleted, which prevents Ocean from fetching/updating the new GKE configuration. In the future, preserve the original node pool instead of deleting it.
To resolve the errors, you can either:
- Create a new node pool with the original pool name. It doesn’t need to run any nodes.
- Delete the cluster in the Spot console (Actions > Delete Cluster) or using the Spot API, then import the cluster in the Spot console or using the Spot API.
Every 30 minutes, an automatic process runs to update the GKE configuration in the control plane manager. You can trigger the process manually.
GKE: Why can't I spin new spot instances (InstanceTaxonomies)?
You can get this message if the instance type is not compatible with the boot disk type:
ERROR, Can't Spin Instance: Name: sin-xxxx. Code: Error, Message: [pd-standard] features and [instance_type: VIRTUAL_MACHINE family: COMPUTE_OPTIMIZED generation: GEN_3 cpu_vendor: INTEL architecture: X86_64 ] InstanceTaxonomies are not compatible for creating instance.
Compare the machine family and PD-standard disk type to decide which is appropriate for your workload.
Contact support to decide on the selected instance type for launching and to remove the problematic instance type or family from the allowlist.
GKE: Why can’t I spin new instances (quota_exceeded)?
You may get this message when scaling up instances:
ERROR, Can't Spin Instance: Name: sin-xxxxx. Code: QUOTA_EXCEEDED, Message: Quota 'M1_CPUS' exceeded. Limit: 0.0 in region us-east4
GCP has allocation quotas, which limit the number of resources that your project has access to. The limit is per region.
Check your current quota. You can request a quota adjustment from GCP.
The prefix in some of the machine names changed from n1 to m1, so will also cause the message to show in the Spot console.
GKE: How can I change the CGROUP_MODE for a GKE cluster?
- Change the cgroup_mode in the GKE node pool.
- Reimport the cluster configuration to Ocean (or roll the cluster/virtual node group for all nodes so they have the latest changes).
EKS, GKE: How do draining timeout and termination grace period work together?
Draining timeout (drainingTimeout) is defined in Ocean. It’s how long Ocean waits for the draining process to end before terminating an instance. The default is 300 seconds.
Termination grace period (terminationGracePeriodSeconds) is defined in Kubernetes. It’s how long Kubernetes waits before terminating the pod. The default is 30 seconds.
You can use Ocean’s draining timeout to make sure the node isn’t terminated before the pod’s application finishes draining. This is helpful if you have applications in pods that need a specific amount of time to gracefully shut down.
If you have a pod that needs time to gracefully shut down, define a terminationGracePeriodSeconds in the pod. In Ocean, set a draining timeout that is greater than or equal to the pod's terminationGracePeriodSeconds time. This way, the node will not terminate before the application in the pod gracefully shuts down.
For example, if you have a 600 second terminationGracePeriodSeconds, make sure your draining timeout in Ocean is more than 600 seconds.
EKS, GKE: Why am I getting the error: when default launchSpec is used as a template only, can't raise target of Ocean?
When the useAsTemplateOnly parameter is true, you cannot edit the target capacity in the Ocean cluster configuration.
Keep in mind that it may not be necessary to increase the target capacity because Ocean automatically scales instances up and down as needed.
If you want to edit the target capacity:
- In the Spot console, go to Ocean > Cloud Clusters, and select the cluster.
- Click Actions > Edit.
- On the Review tab, click JSON > Edit Mode.
- Go to Compute > launchSpecification.
- Change the useAsTemplateOnly parameter to false.
This will let you manually increase the target of the cluster and the nodes will launch in the default virtual node group.
AKS, EKS, GKE: Why is there a difference in node utilization in AWS and the Spot console?
When you look in the Spot console (Ocean > Cloud Clusters > node > Nodes), the memory and CPU are requests by pod. The requests are grouped at the node. This is the pod allocation.
When you look in the AWS console, you can see the actual utilization, which is different than the allocation.
AKS, EKS, GKE: How can I schedule the Ocean Controller?
By default, the controller pod has priorityClassName system-node-critical, so it has guaranteed scheduling.
You can make sure the Ocean Controller is always running by setting the minimum capacity in the cluster or virtual node group to at least 1. This means there is always a node running in the controller’s pod.
AKS, EKS, GKE: Can I use a static endpoint with Ocean Controller Version 2?
A dynamic endpoint can change with scaling or other operational activities.
A static endpoint in cloud computing is a fixed, unchanged network address used to access a resource or service reliably. This lets applications and users connect to a stable address that doesn’t change.
You can set a static endpoint to use with Ocean Controller Version 2:
- Install the latest controller Helm chart and update the ocean-kubernetes-controller.
- When you’re installing ocean-kubernetes-controller, also include:
--set spotinst.baseUrl=https://api-static.spotinst.io.
AKS, EKS, GKE: Why can’t I upgrade the Ocean Controller Version 2 using Helm?
If you get this message when you’re upgrading the Ocean Controller Version 2 using Helm:
Release "ocean-controller" does not exist. Installing it now.
Error: parse error at (ocean-kubernetes-controller/templates/_helpers.tpl:320): unclosed action
You need to:
- Check if the cluster already has the metrics-server installed:
kubectl get apiservice v1beta1.metrics.k8s.io. - Check the Helm Charts version:
helm search repo spot. - Update the Helm Chart to the latest version.
If these don’t work, add the --set metrics-server.deloyChart=false flag to the helm upgrade –install cmd.
AKS, EKS, GKE: Should I get frequent SelfSubjectAccessReview requests after upgrading to Ocean Controller Version 2?
After you upgrade to Ocean Controller Version 2, you may get many SIEM alerts due to SelfSubjectAccessReview requests to your API server. This is expected behavior.
With the Version 2 Ocean Controller, Spot gets reports for any custom resource you gave it access to through the controller cluster role. For example, an Argo Rollouts custom resource or a VerticalPodAutoscaler for rightsizing. These require Spot to list the custom resources in the cluster and make sure there's read access. This happens when the controller starts up and on a regular basis when it's running.
AKS, EKS, GKE: How long are Ocean Controller logs kept for?
The Ocean Controller saves up to 8 days of logs. The logs for each day are about 11 MB.
- Sign in to the container:
kubectl exec -ti <controller_pod_name> bash -n spot-system. - View the logs:
ls -lah controller/log/spotinst.
AKS, EKS, GKE: Why is rightsizing information not showing after installing the metrics server?
Rightsizing data may not show after installing the metrics server:
-
Make sure you’re using the latest version of the controller. It takes around 4 days for the metrics to show after upgrading.
-
If you’re using an EKS cluster, make sure you have 2 security groups:
- Worker node group with an inbound rule that allows communication with the control plane’s security group through port 443.
- Cluster’s control plane.
-
Check the common issues with the metrics server.
AKS, EKS, GKE: Why is the out of strategy replacement getting canceled for pods without the restrict-scale-down label?
If a node replacement is canceled, you may see this log message in the cluster in the Spot console:
DEBUG, Replacement of type Out of strategy for instance has been canceled. Reason for cancellation: A pod with the restrict-scale-down label is currently running on the node.
You can also get this message if you’re using the cluster-autoscaler.kubernetes.io/safe-to-evict label. It works the same as the restrict-scale-down label. When you have one of those labels, the node is not scaled down or replaced.
Make sure that labels and annotations don’t prevent scaling down on the virtual node groups or on the pods.
AKS, EKS, GKE: What are the minimum permissions needed for a programmatic token for creating an Ocean cluster controller?
You can use a programmatic token for creating Ocean cluster controllers. The benefit of programmatic tokens is they aren't linked to a specific user. If the user is deleted, it doesn't affect the Ocean controller. This helps prevent interruptions and heartbeat issues.
At minimum, the token must have account viewer permissions. Viewer permission is the only permission required for a cluster controller to operate. Cluster controllers don't manage resources in Ocean, the autoscaler does. If you want this same programmatic user to manage other resources in your cluster, additional permission policies are required.
For a network client, only the account viewer permission is required for the client to operate.
AKS, EKS, GKE: Why do I have an unscheduled DaemonSet pod?
DaemonSet pods are scheduled by the Kubernetes scheduler when nodes boot up in the cluster.
Ocean autoscaler does not trigger a launch of a new node to serve a DaemonSet pod. This is by design. In addition, the DaemonSet pod doesn’t trigger scale-up.
AKS, EKS, GKE: Can my Kubernetes pods tolerate all taints?
You may have critical workloads in your Kubernetes cluster that require constant high availability. You don’t want specific node taints to block these critical pods from being scheduled.
You can add a universal toleration to your workloads to allow these pods to tolerate any and all taints.
AKS, EKS, GKE: Why are my pods unscheduled with event: pod has unbound immediate PersistentVolumeClaims?
You may get this event in your Kubernetes cluster:
0/3 nodes are available: pod has unbound immediate PersistentVolumeClaims
This can happen because:
- Kubernetes needs storage classes to create the persistent volumes for persistent volume claims (PVCs) dynamically. Make sure you have storage classes configured unless you’re using static persistent volume claims.
- The persistent volume and persistent volume claims access modes don’t match.
- The persistent volume capacity is less than the persistent volume claim.
- The total number of persistent volume claims is higher than the persistent volume.
AKS, EKS, GKE: Why is my pod unschedulable (autoscaling disabled)?
If the Ocean autoscaler scales up an instance for your pod at least 5 times, but the Kubernetes scheduler can’t schedule the pod, you may get this message:
WARN, Pod Metrics-Server-xxxxx Has Failed To Schedule For 76 Minutes. Autoscaling Disabled For Pod Metrics-Server-xxxxx
WARN, Pod Redis-0 Has Failed To Schedule For 76 Minutes. Autoscaling Disabled For Pod Redis-0
WARN, Pod Kube-Dns-Autoscaler-xxxxx Has Failed To Schedule For 76 Minutes. Autoscaling Disabled For Pod Kube-Dns-Autoscaler-xxxxx
WARN, Pod Worker-Deployment-xxxxx Has Failed To Schedule For 76 Minutes. Autoscaling Disabled For Pod Worker-Deployment-xxxxx
WARN, Pod Kube-Dns-xxxxx Has Failed To Schedule For 76 Minutes. Autoscaling Disabled For Pod Kube-Dns-xxxxx
Ocean stops trying to scale up this pod to prevent infinite scaling.
This can happen if:
- Ocean launches instances for the pending pod but they don’t fully register to the Kubernetes cluster because the pod has no node to schedule.
- You’re using AWS ebs-csi-driver PV/PVC. It’s possible that the ebs-csi-node DaemonSet pods are not running on the nodes. This can happen if the DaemonSet object is having issues, the DaemonSet pods are not running, or if taints on a custom virtual node group are stopping the DaemonSet pods from being scheduled on the node. If you’re using DaemonSet, then the DaemonSet pods must run on every node if a pending pod has a PVC.
- You’re using GPU nodes. The Nvidia GPU DaemonSet is required to run on every GPU node for the nodes to expose their GPU resources. If a pending node is requesting GPU, then Ocean launches a GPU instance. You need to make sure the nodes are exposing the GPU resources. Typically, you do this with the Nvidia GPU DaemonSet. If the DaemonSet has issues, then the pod may not be scheduled on the node because the node won’t be exposing the GPU.
AKS, EKS, GKE: Why am I getting a Java heap space message (OutOfMemoryError)?
You may see this message in the logs if you use Prometheus to scrape Ocean metrics:
ERROR 1 --- java.lang.OutOfMemoryError: Java heap space with root cause
java.lang.OutOfMemoryError: Java heap space
This means the application ran out of Java heap space, and the pod will crash temporarily. You may also see that the target on the Prometheus dashboard is down.
Use the JAVA_OPTS variables to increase the minimum and maximum heap space the application can use. You can use podEnvVariables in the helm chart and set JAVA_OPTS="-Xms256m -Xmx1g".
Set the amounts according to the needs of your pods.
AKS, EKS, GKE: Why am I getting a Kubernetes Autoscaler, Deadlock for Pod error?
You get this error in the log:
Kubernetes Autoscaler, Deadlock for Pod: '{pod-name}'
Can't scale up an Instance since PersistentVolumeClaim:
'{PVC-name}'
VolumeId: '{vol-name}' is already attached to an existing Instance:
'{instance-ID}' Please consider using a new PersistentVolumeClaim or open a
support ticket.
This can happen when the pod has a claim for a specific volume attached to a different instance, and that instance does not have free space for the pod.
By freeing up space, the pod can be placed on its attached node and can use the volume it claimed.
AKS, EKS, GKE: Can pods requiring HostPort cause underutilized nodes (Kubernetes)?
If multiple pods request the same port (hostPort), each pod will get the hostPort, but each pod will be scheduled separately on its own node.
Avoid using the hostPort request, unless it’s necessary (Kubernetes - configuration best practices).
AKS, EKS, GKE: What’s the difference between Kubernetes ResourceQuota and LimitRange objects?
A resource quota is defined by a ResourceQuota object. It limits aggregate resources, such as CPU, memory, and GPU consumption per namespace. If creating or updating a resource violates a quota constraint, the request will fail with HTTP status code 403 FORBIDDEN with a message explaining the constraint that would have been violated. You can see the messages using: kubectl get events
A limit range is a policy to constrain the resource allocations (limits and requests) that you can specify for each applicable object kind (such as Pod or PersistentVolumeClaim) in a namespace.
ResourceQuota is used to limit the total resource consumption of a namespace.
LimitRange manages constraints at a pod and container level within the project.
AKS, EKS, GKE: Can I configure headroom for a node?
You cannot add headroom at a node level. Headroom is intended for:
- Fast scaling: the infrastructure is ready, no need to wait for scaling.
- Interruption: there is available capacity for the pod. If the headroom is all on one node and the node is interrupted, then there is no headroom that is readily available.
AKS, EKS, GKE: Can I configure automatic headroom using Kubernetes Operations (kOps)?
You can configure automatic headroom using kOps at the cluster level, not at a virtual node group level. Add these metadata labels:
spotinst.io/autoscaler-auto-config: "true"
spotinst.io/autoscaler-auto-headroom-percentage: "20"
spotinst.io/ocean-default-launchspec: "true"
Here's an example of a config file:
apiVersion: kops.k8s.io/v1alpha2
kind: InstanceGroup
metadata:
name: "test-vng-2"
labels:
kops.k8s.io/cluster: "erez-via-2.ts.ek8s.com"
spotinst.io/spot-percentage: "50"
spotinst.io/autoscaler-auto-config: "true"
spotinst.io/ocean-default-launchspec: "true"
spotinst.io/autoscaler-auto-headroom-percentage: "20"
spotinst.io/autoscaler-headroom-num-of-units: "2"
spotinst.io/autoscaler-resource-limits-max-vcpu: "2"
spotinst.io/autoscaler-headroom-mem-per-unit: "1024"
spotinst.io/autoscaler-headroom-gpu-per-unit: "0"
spec:
role: Node
maxSize: 1
minSize: 1
AKS, EKS, GKE: Can I stop Kubernetes workloads from scaling down in Ocean?
You can restrict specific pods from scaling down by configuring Ocean and Kubernetes. The instance will be replaced only if:
- It goes into an unhealthy state.
- Forced by a cloud provider interruption.
There are two options for restricting pods from scaling down:
-
Kubernetes deployments/pods: spotinst.io/restrict-scale-down: true
Use the
spotinst.io/restrict-scale-downlabel set to true to block proactive scaling down for more efficient bin packing. This will leave the instance running as long as possible. It gets defined as a label in the pod's configuration. See restrict scale down. -
Virtual node group (VNG): restrict scale down (only available for AWS, ECS, and GKE)
You can configure Restrict Scale Down at the virtual node group level so the nodes and pods within the virtual node group are not replaced or scaled down due to the auto scaler resource optimization. Create a virtual node group, go to the Advanced tab, then select Restrict Scale Down.
AKS, EKS, GKE: How do I stop autoscaler and recoveries?
You can stop the autoscaler and recoveries:
- Disable autoscaling.
- Stop recoveries:
- In the Spot console, go to Ocean > Cloud Clusters and select a group.
- On the Nodes tab, select the node and click Actions > Detach.
- In the AWS console, detach any new nodes.
If you need to restart autoscaling and recoveries, enable autoscaling.
AKS, ECS, EKS, GKE: Why does Ocean fail to update instance types?
You cannot update the instance types in the default virtual node group. For example, it’s not supported to remove m4.large and m5.large, add m5d.xlarge and m6i.xlarge to the default virtual node group, and then update the cluster.
If you do, you’ll get this error:
Launch spec ols-xxxxxxxx instance types are not a subset of ocean cluster
Remove the instance types at the cluster level, add m5d.xlarge and m6i.xlarge instance types, and then update the cluster.
Instance types of the virtual node group are always a subset of the Ocean cluster.
AKS, ECS, EKS, GKE: Can I include or exclude instance types in my Ocean cluster?
You can include or exclude certain instance types in your Ocean cluster. Typically, you do it from the cluster configuration.
- Blacklist: instance types to block launching in the Ocean cluster. It cannot be used with a permit list.
- Whitelist: instance types allowed in the Ocean cluster. It cannot be used with a deny list.
- Filtering: list of filters. The instance types that match with all filters make up the Ocean's whitelist parameter. Filtering cannot be used with allow or block lists.
You can allow, block, or filter instance types in the cluster configuration in compute: instanceTypes in the cluster’s JSON or using an API.
AKS, ECS, EKS, GKE: Why is the cost analysis in the Ocean dashboard unusually high for yesterday?
Cost Analysis in the Ocean Dashboard can show an unusually high cost for yesterday.
If you look at the same day a few days later, the cost will be similar to the other days.
Spot's Cost Analysis reviews the cost data after one day. For instance, if today is August 20, the cost analysis data will be finalized only on August 21.
Initially, the costs are compared with the on demand value of the instance types, followed by the Spot value. Afterwards, the costs are compared with reserved instances and saving plans. So, if the you have reserved instances and saving plans configured, the cost gap from the previous day can be higher.
AKS, ECS, EKS: Why did an instance launch even though the autoscaler is disabled?
If you have shutdown hours set up and autoscaler is disabled, you may see one of these messages in the Spot console:
Info Instances: [i-xxxxx] have been launched. Reason: Shutdown hours period finishedInfo Instances: [i-xxxxx] have been detached. Reason: Scale-down as part of instance recoveryInfo Instances: [i-xxxxx] have been launched. Reason: Scale-up as part of instance recovery
If shutdown hours are set up and autoscaler is disabled, new nodes are not scaled up based on pending pods. An existing node is still launched:
- At the end of the shutdown hours.
- If the spot node launched at the end of shutdown hours has an interruption or recovery.
You can disable shutdown hours in the Spot console: go to Ocean > Cloud Clusters > select the cluster > Actions > Customize Scaling > Cluster Shutdown Hours.
AKS: Why won't my cluster scale up (parsing version)?
If your Ocean cluster won’t scale up, you may see a message like this in the Spot console logs:
Failed to perform scale up for virtual node group xxxxx (vng-xxxxx). Got status code different from SC_OK : 400 Body { "code": "BadRequest", "details": null, "message": "Client Error: error parsing version(1.26). If you would like to use alias minor version, please use api version starting from 2022-03-02-preview", "subcode": "" }
This happens when the Ocean cluster tries to create a node pool using a specific Kubernetes version. In this message, it’s version 1.26.
- If you want to use a specific version, you also need to give the exact patch version (the alias minor version).
- You also need to make sure your AKS API version is at least the version mentioned in the message.
AKS: Why are my pods failing after scheduling (b-series/burstable VMs)?
If your pods are scheduled on B-series nodes, the nodes and VMs are burstable. This means that they outperform their actual limits for a short period. After the burst credits are used, the pods will fail, and you may see this message:
The node was low on resource: memory. Threshold quantity: 750Mi, available: 757424Ki. Container terrakube-registry was using 339556Ki, request is 0, has larger consumption of memory.
You can:
- Make sure your resource allocation is set up correctly. You can use the resource quotas and limit ranges as a reference.
- Exclude b-series (Bs) nodes from your virtual node groups.
- Set up rightsizing recommendations.
AKS: Why is my node not registering in my AKS cluster (UDRWithNodePublicIPNotAllowed)?
If your pods are not registering in your AKS cluster, you may get this message:
Could not scale up for pending pod xxxxx due to technical failure to launch required instances. Scale down has been disabled in the cluster until pod is scheduled.
ERROR Failed to perform scale up for virtual node group xxxxx (vng-xxxxx). Got status code different from SC_OK : 400 Body { "code": "UDRWithNodePublicIPNotAllowed", "details": null, "message": "OutboundType UserDefinedRouting can not be combined with Node Public IP.", "subcode": "" }
ERROR Failed to scale up 1 new nodes as part of scaling the virtual node groups vng-xxxxx (xxxxx).
You cannot use enableNodePublicIP set to True with userDefinedRouting set to outboundType.
If you’re using outbound types of userDefinedRouting, change "enableNodePublicIP": true, to ``false. For example:
{
"nodePoolProperties": {
"maxPodsPerNode": 250,
"enableNodePublicIP": false
}
}
AKS: Why can’t I migrate a workload for an AKS Ocean cluster?
The Start Migration button can be grayed out for an AKS Ocean cluster if:
- The cluster has system node pools, which must run as regular nodes and don’t require scaling.
- The Kubernetes cluster isn’t running on AKS infrastructure.
- Kubernetes cluster isn’t connected to an Ocean cluster. You can import an AKS cluster to Ocean.
- The Ocean Controller wasn’t installed, updated, and running in the cluster.
- Cluster or virtual node group doesn’t have a supported Kubernetes version.
- You don’t have dedicated virtual node groups for your workload to let Ocean autoscaler scale up nodes.
AKS: How do I view the current spot percentage for an Ocean AKS Ocean cluster?
AKS Ocean calculates spot percentage by vCPU resources (not by node count). To view the correct representation of spot percentage by vCPU, check the vCPU Ocean managed resources lifecycle percentage to confirm that the actual spot percentage of running nodes aligns with the defined value.
A small gap between the actual vCPU spot percentage and the defined value may still exist because Ocean performs bulk scale-up and scales nodes from the same node pool and lifecycle simultaneously.
Ocean autoscaler does not take spot percentage into consideration during bin-packing/scale-down actions. This is only taken into consideration during scale-ups.
AKS: Why is the workload marked as unable to migrate?
If you’re seeing an unable to migrate status in workload migration, check if the node affinity has kubernetes.azure.com/scalesetpriority. Do not use this nodeAffinity. If you have both the Spot toleration and nodeAffinity configured, then Ocean autoscaling fails. You can see a message in the cluster log in the Spot console.
AKS: Can I create VMs with specific architecture in Ocean AKS?
You may want to run workloads (pods) on VMs with a specified architecture.
For Ocean clusters (AWS), you can use an AMI with the required architecture. Update the AMI in the cluster or virtual node group (VNG) configuration to make sure the instances are launched according to the architecture specified in the AMI.
However, it’s not possible to do with Ocean AKS clusters because you cannot choose a particular image to run VMs when you create an AKS cluster.
- Create a new virtual node group in the Ocean AKS cluster and configure it manually or import the configuration of a node pool.
- Add vmSizes to the virtual node group JSON file.
"vmSizes": {
"filters": {
"architectures": [
"x86_64"
],
"series": []
}
}
-
Architectures is a list of strings, and the values can be a combination of x86_64 (includes both intel64 and amd64), intel64, amd64, and arm64.
-
Add series with the VM series for the particular architecture.
For example, run VMs with arm64 and launch the VMs with Dps_V5 as the series.
AKS: Can I inject spot toleration for a cluster with shutdown hours?
If you use spot toleration injection in clusters configured with shutdown hours, Ocean will launch regular VMs in addition to the spot VMs once the shutdown hours are finished. This happens even if the Spot % is set to 100% because the regular VMs are created before the Ocean webhook boots up.
You can force the pods to wait until the admission controller pods are running, to make sure that toleration is added to the workload.
Do not set this up on production clusters because if the admission controller pods are failing or stuck, you can get pending pods.
-
Edit the webhook configuration:
kubectl edit MutatingWebhookConfiguration spot-admission-controller.kube-system.svc. -
Make sure this object is in the configuration file:
objectSelector:
matchExpressions:
- key: app.kubernetes.io/name
operator: NotIn
values:
- spot-admission-controller
- If the object is not there, reinstall the Spot admission controller.
- Change
failurePolicyto Fail (failurePolicy: Fail).
AKS: Why are on-demand nodes running in my virtual node groups?
If you have virtual node groups with Spot % set to 100 or Fallback to Regular set to off, you can still have on-demand nodes running.
This can happen if you have nodes in a kube-system namespace. Kube-system pods are created by the Kubernetes system and are required to make the cluster work.
AKS only launches spot nodes if the admission controller is enabled and Spot tolerations are injected into the pods.
AWS, GCP: How is Ocean storage cost calculated?
Ocean Cost analysis reflects Persistent Volume (PV) storage costs from AWS EBS or GCP Persistent Disk, and is based on the following steps:
- Ocean collects hourly usage data, including storage volume size, volume ID, and hourly price.
- Persistent Volume Claims (PVC) costs:
- Ocean considers all pods in the cluster with PVCs and calculates the relevant cost for each pod as (pod run time)*(storage pricing) using the corresponding PV object and its mapped storage volume. Storage pricing is obtained from Step 1.
- Ocean aggregates the PVC costs for the given pod.
- Ocean presents storage costs broken down per workload per hour and calculates aggregated costs for standalone pods in the cluster.
The default storage configuration in Kubernetes is non-persistent or temporary. Data is stored in the host's temporary storage directory as long as the container exists. When the container shuts down, the data is removed.
Ocean for Apache Spark
Can I set the number of retries for a stage in Ocean Spark?
If there is a stage failure when a job runs in Ocean Spark, there’s a retry mechanism. You can change the number of retries for a stage:
- In the Spot console, go to Ocean for Spark > Configuration Templates.
- Select the configuration template of the application you need to change.
- Add
spark.stage.maxConsecutiveAttemptswith the number of retries.
Can I run Spark jobs on the driver, not on executors?
Yes, you can define your configuration template to run your Spark application on the driver and not on the executors.
Define a Jupyter kernel with a low idle timeout so it’s scaled down quickly if it’s not in use:
"spark.dynamicAllocation.enabled": "true",
"spark.dynamicAllocation.maxExecutors": "1",
"spark.dynamicAllocation.minExecutors": "0",
"spark.dynamicAllocation.initialExecutors": "0",
"spark.dynamicAllocation.executorIdleTimeout": "10s"
Why are requested virtual node groups not declared for the target cluster?
You attempt to schedule a job but receive the following error:
failureReason": "The requested VNGs are not declared for the target cluster.", "recoverySuggestion": "Please make sure you did not write typos in VNG names or declare the missing VNGs."
Check the request body.If one or more VNG IDs appear under unknownVNGIds, you must attach them to the Ocean Spark cluster in the console and in the Spot API.
Available virtual node groups will be selected automatically if you do not explicitly specify them. The available virtual node groups in the response are the virtual node groups attached to the Spark cluster.
Why are my pods going to the wrong virtual node group?
If your Ocean Spark pods are going to the wrong virtual node group, it’s typically because the virtual node group was updated or deleted.
You can either recreate the Ocean Spark cluster or update the labels and taints. These are the definitions for virtual node group labels and taints:
ocean-spark-system
"labels": [
{
"key": "nodegroup-name",
"value": "ofas-system"
}
],
"taints": [],
ocean-spark-on-demand
"labels": [
{
"key": "bigdata.spot.io/vng",
"value": "ocean-spark"
},
{
"key": "nodegroup-name",
"value": "ocean-spark-on-demand"
}
],
"taints": [
{
"key": "bigdata.spot.io/unschedulable",
"value": "ocean-spark",
"effect": "NoSchedule"
}
],
ocean-spark-spot
"labels": [
{
"key": "bigdata.spot.io/vng",
"value": "ocean-spark"
},
{
"key": "nodegroup-name",
"value": "ocean-spark-spot"
}
],
"taints": [
{
"key": "bigdata.spot.io/unschedulable",
"value": "ocean-spark",
"effect": "NoSchedule"
}
],
What are the minimum permissions for creating a workspace?
You can give some of your users access to a workspace but not allow them to make changes to a cluster.