Product Tour
This section takes you through a tour of the main pages of Ocean for Apache Spark (also referred to as Ocean Spark): Clusters, Applications, and Jobs. Let’s first define these major concepts.
Clusters
Clusters make up the compute infrastructure on which your Spark applications run. These Kubernetes clusters are typically long-running clusters. After initially provisioning them, most people let them run 24x7. Clusters do not have a fixed size. Ocean takes care of automatically scaling them up and down (by adding or removing nodes, based on the load), so that your costs are minimized if few or no Spark applications are running.
Distinct Spark applications running on the same cluster are isolated from each other. Each Spark application can run its own Docker image with its own Spark version. For this reason, many customers choose to use a single cluster to run all their Spark applications. Another common setup is to have one cluster per cloud account and environment (e.g., dev, staging, prod), or one cluster per cloud region (e.g., us-west, us-east).
Ocean Spark lets you manage clusters in a self-service way.
Applications
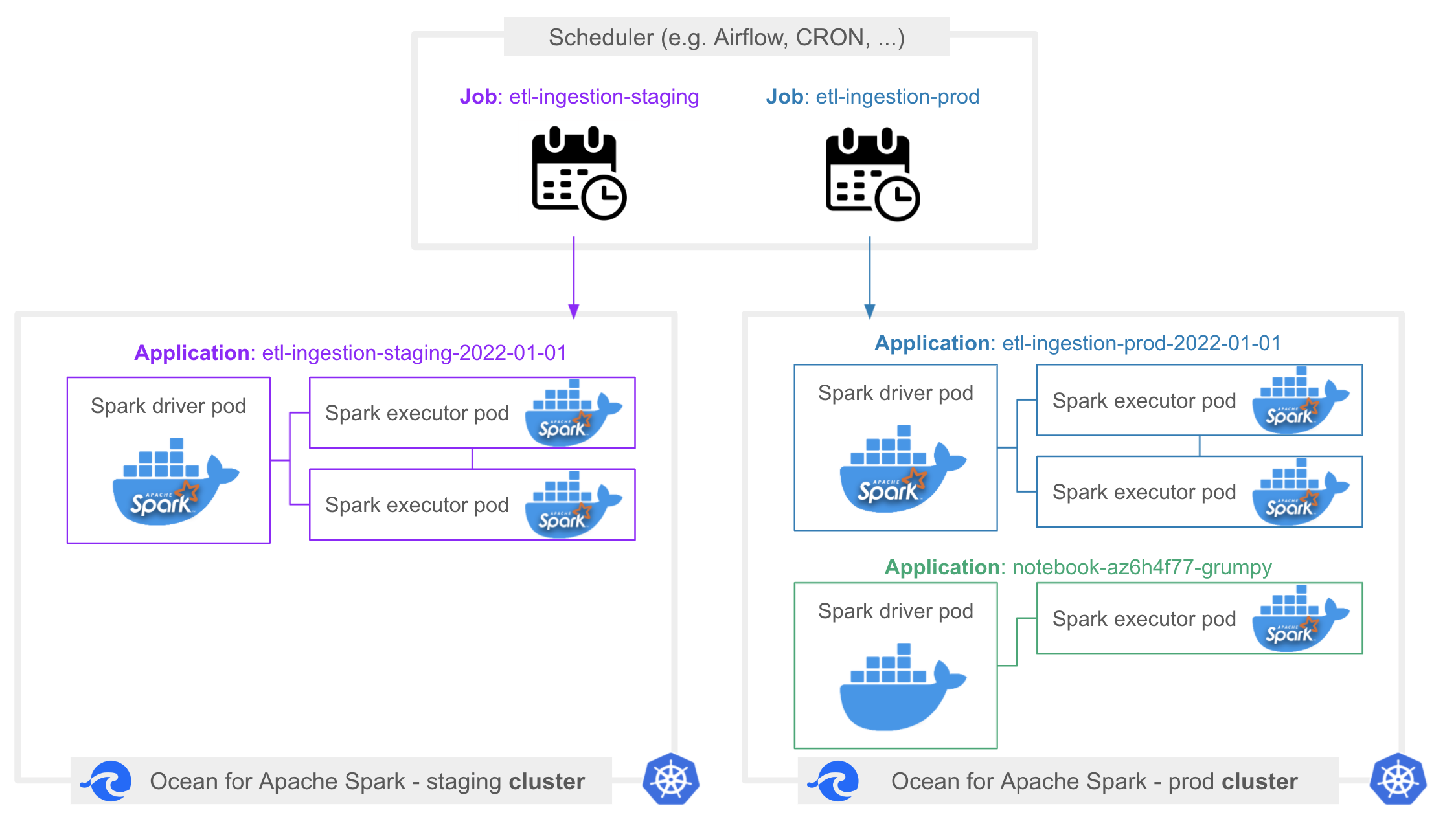
A Spark application is the runtime execution of Spark code, submitted interactively through a notebook or as a file to execute through an API call. When you submit a Spark application on a cluster, Kubernetes first needs to schedule the Spark driver pod, which means placing it on a Kubernetes node by reusing existing capacity or provisioning a new node. Kubernetes then downloads the application’s Docker image, and runs it. Once the Spark driver has started, it will request Spark executors, which will be scheduled on the same cluster. A Spark application is therefore made of one Spark driver (one pod), and a variable number of Spark executors (one executor = one pod).
Even if you have multiple clusters (hosted in the same cloud account), Ocean for Apache Spark lets you monitor the applications running on these clusters on a single dashboard.
Jobs
A Spark job is a logical grouping of Spark applications which you explicitly define when you submit Spark applications, as the Spark job identifier is a required field in our REST API. Applications belonging to the same job are also called executions of the job.
For example, you could define a job with the ID daily-etl-ingestion. This job would be scheduled on a daily basis from Airflow, and then applications within this job could be daily-etl-ingestion-2022-01-01, daily-etl-ingestion-2022-01-02, daily-etl-ingestion-2022-01-03, etc.
The interest of grouping Spark applications together within a job is that you get a dedicated dashboard where you can track all the executions of your job and view relevant metrics and trends (e.g., duration, cloud costs, and volume of data read and written). Ocean Spark can automatically tune specific infrastructure parameters and Spark configurations at the level of a job by learning from the historical performance characteristics of previous executions of the job.
A job belongs to a specific cluster, but the main Jobs dashboard gives you visibility over all the jobs you have defined across all your clusters (as long as these clusters are hosted in the same cloud account).
A notebook is a special type of Spark application which does not belong to any job.
Related Topics
- Continue the Product Tour and learn how to manage your clusters.
- Get started with your first cluster in Ocean for Apache Spark.