Run Your First App
Now that you have created your first Ocean Spark cluster, you are ready to run your first app.
Prerequisites
To run your first app, you will need to have:
- The Ocean Spark cluster ID of the cluster you just created (of the format osc-e4089a00). You can find this in the console in the list of clusters, or by using the Get Cluster List in the API.
- A Spot token to interact with Spot API.
- A Spot Account ID, this can be found in the same menu location as the API key
Using the Ocean Spark API, you can run, configure, and monitor applications using the different endpoints available.
To know more about the API endpoints and parameters, check out the API reference.
Run Pi App
The command below will run the classic Monte-Carlo Pi computation contained in all Spark distributions:
curl -k -X POST \
'https://api.spotinst.io/ocean/spark/cluster/<your cluster id>/app?accountId=<your accountId>' \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer ...' \
-d '{
"jobId": "spark-pi",
"configOverrides":
{
"type": "Scala",
"sparkVersion": "3.2.0",
"mainApplicationFile": "local:///opt/spark/examples/jars/examples.jar",
"image": "gcr.io/ocean-spark/spark:platform-3.2-latest",
"mainClass": "org.apache.spark.examples.SparkPi",
"arguments": ["1000"],
"executor": {
"instances": 1
}
}
}'
Here's a breakdown of the payload:
- We assign the job ID "spark-pi" to the application. A job is a logical grouping of applications. It is typically a scheduled workload that runs every day or every hour. Every run of a job is called an application in Ocean Spark. In the console, the Jobs view lets you track performance of jobs over time. A unique app ID will be generated from the job ID (although you can specify one yourself).
- Default configurations are overridden in configOverrides:
- This is a Scala application running Spark 3.2.0.
- The command to run is specified by mainApplicationFile, mainClass, and arguments.
The API then returns something like:
{
"request":{
"id":"39e2b4a4-46c9-4ff3-bc3a-e5d3f2432549",
"url":"/ocean/spark/cluster/osc-e4089a00/app",
"method":"POST",
"timestamp":"2021-11-14T21:28:35.546Z"
},
"response":{
"status":{
"code":200,
"message":"OK"
},
"kind":"spotinst:ocean:spark:application",
"items":[
{
"internalId":"8ec73ba0-c7df-4b25-b21e-efaeb7c4bfe2",
"id":"spark-pi-2a201099-4ce9-4220-805e-049363174528",
"displayName":"spark-pi-2a201099-4ce9-4220-805e-049363174528",
"accountId":"act-27419163",
"organizationId":606079874885,
"userId":42,
"clusterId":"osc-e4089a00",
"controllerClusterId":"arnar-rokkar-111",
"appState":"NEW",
"submissionSource":"public-api",
"createdAt":"2021-11-14T21:28:35.546Z",
"updatedAt":"2021-11-14T21:28:35.546Z",
"job":{
"id":"spark-pi",
"displayName":"spark-pi"
},
"config":{
"type":"Scala",
"sparkVersion":"3.2.0",
"image":"gcr.io/ocean-spark/spark:platform-3.2.0-dm15",
"mainApplicationFile":"local:///opt/spark/examples/jars/examples.jar",
"mainClass":"org.apache.spark.examples.SparkPi",
"arguments":[
"1000"
],
"sparkConf":{
"spark.kubernetes.allocation.batch.size":"10",
"spark.sql.execution.arrow.enabled":"true",
"spark.kubernetes.allocation.driver.readinessTimeout":"120s",
"spark.sql.execution.arrow.pyspark.enabled":"true",
"spark.sql.execution.arrow.sparkr.enabled":"true",
"spark.sql.adaptive.enabled":"true",
"spark.storage.decommission.shuffleBlocks.enabled":"true",
"spark.storage.decommission.rddBlocks.enabled":"true",
"spark.storage.decommission.enabled":"true",
"spark.decommission.enabled":"true",
"spark.dynamicAllocation.enabled":"false",
"spark.dynamicAllocation.shuffleTracking.enabled":"true",
"spark.dynamicAllocation.executorAllocationRatio":"0.33",
"spark.dynamicAllocation.sustainedSchedulerBacklogTimeout":"30",
"spark.cleaner.periodicGC.interval":"1min"
},
"driver":{
"cores":4,
"coreRequest":"3460m",
"memory":"8192m",
"envVars":{
"KUBERNETES_REQUEST_TIMEOUT":"30000",
"KUBERNETES_CONNECTION_TIMEOUT":"30000"
},
"instanceType":"m5.xlarge",
"spot":false
},
"executor":{
"cores":4,
"instances":1,
"coreRequest":"3460m",
"memory":"8192m",
"instanceType":"m5.xlarge",
"spot":true
},
"priority":"normal"
}
}
]
Note that some additional configurations are automatically set by Ocean Spark. In particular, the appId is a unique identifier of this Spark application on your cluster. Here it has been generated automatically from the jobId, but you can set it yourself in the payload of your request to launch an app.
Beside the appId, Ocean Spark also set some defaults to increase the stability and performance of the app. Learn more about configuration management and auto-tuning.
The application you just created should appear in the Ocean Spark console:
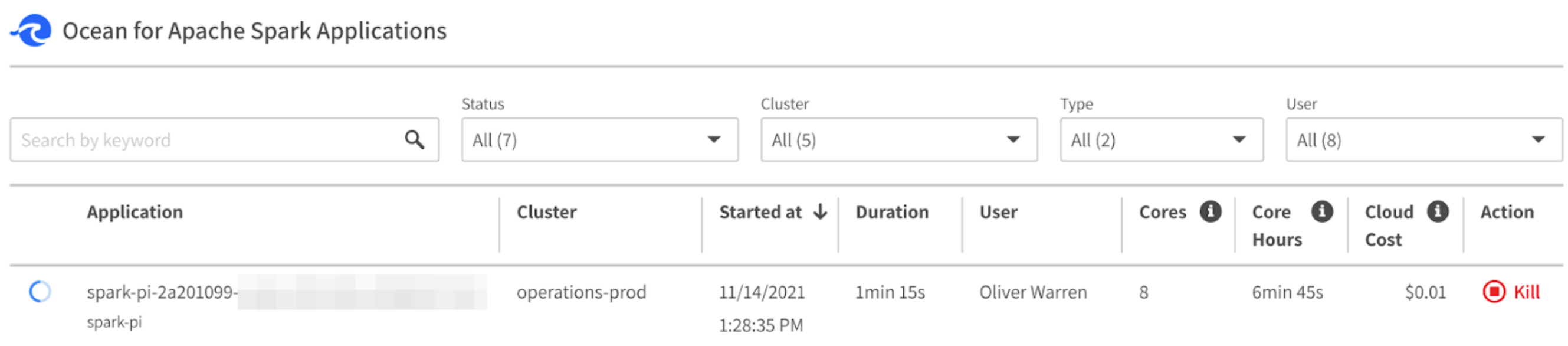
Clicking on the application name opens the application details page. At this point, you can open the Spark UI, follow the live log stream, or kill the app.
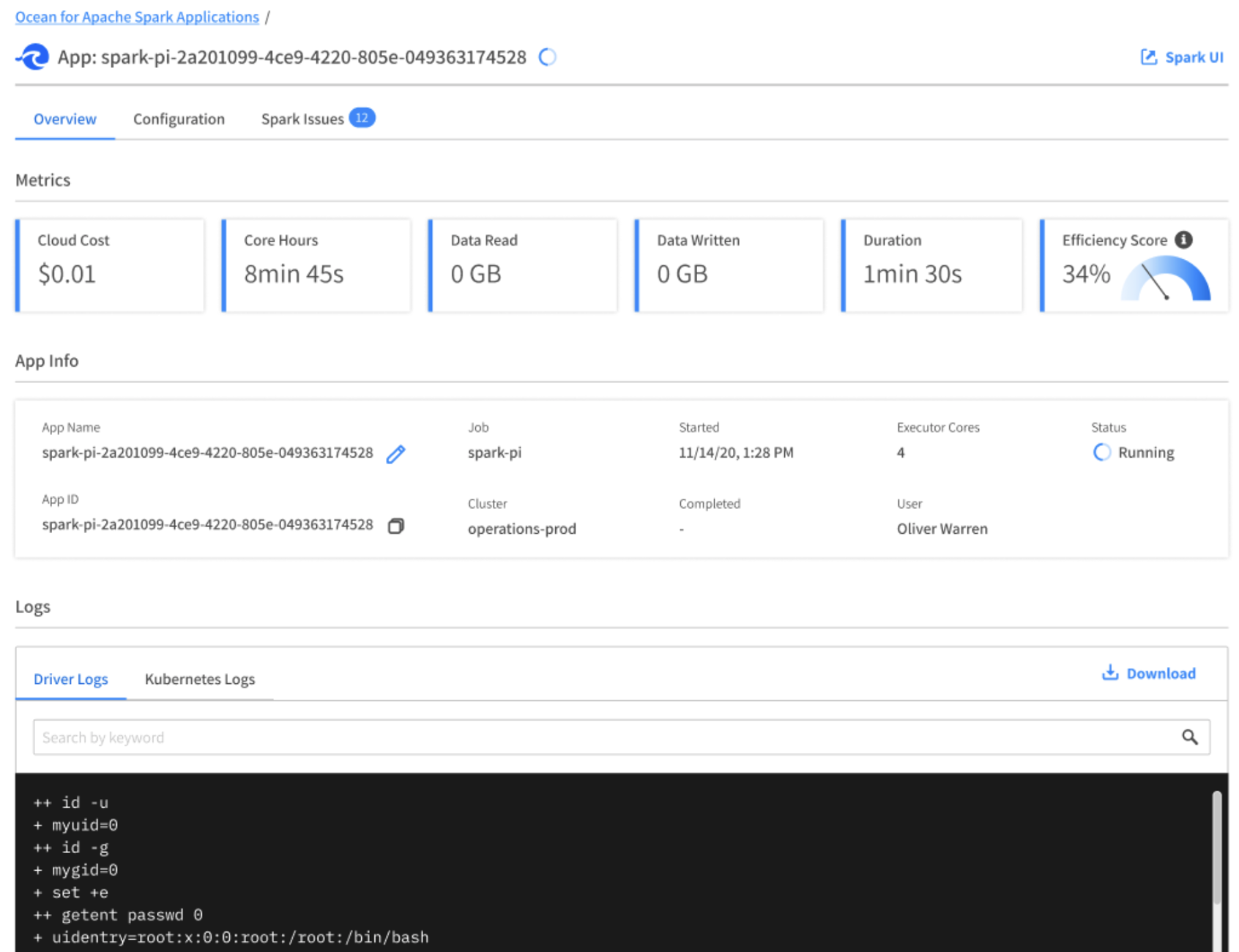
This example uses a JAR embedded in the Spark Docker image and neither reads nor writes data. For a more real-world use case, learn how to access your own data.
What's Next?
Take the Ocean Spark Product Tour where you will learn how to manage your clusters, view cluster details, and much more.